自然语言处理(序章):我爱自然语言处理(I)
昨天浏览了一下我爱自然语言处理站点上的全部文章,然后基本过滤下来自己感兴趣的90篇左右的文章,这一阵子就先把这90篇文章认认真真看完吧,总结看的过程中自己感兴趣而且重要的点,遂成此文。本文中所有资料属我爱自然语言处理及博客原文引用作者所有,特此声明。
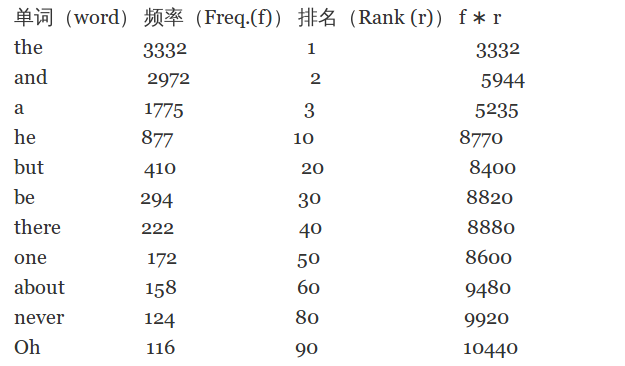
齐夫定律(Zipf’s Law)
Zipf's Law:
在任何一个自然语言里第$n$个最常用的单词的频率与$n$近似成反比(The frequency of use of the nth-most-frequently-used word in any natural language is approximately inversely proportional to n).更正式地,我们可以说:存在一个常量$k$,使得:
\begin{equation} f \times r =k \end{equation}
其中$f$表示单词出现的频度,$r$表示单词出现次数的排名(RANK).
北京大学姜望琪老师的《Zipf与省力原则》讲得很好,部分摘录如下:
- 省力原则(the Principle of Least Effort),又称经济原则(the Economy Principle),可以概括为:以最小的代价换取最大的收益。这是指导人类行为的一条根本性原则。在现代学术界,第一个明确提出这条原则的是美国学者 George Kingsley Zipf。
- George Kingsley Zipf1902年1月出生于一个德裔家庭(其祖父十九世纪中叶移居美国)。1924年,他以优异成绩毕业于哈佛学院。1925年在德国波恩、柏林学习。1929年完成Relative Frequency as a Determinant of Phonetic Change,获得哈佛比较语文学博士学位。然后,他开始在哈佛教授德语。1931年与Joyce Waters Brown结婚。1932年出版Selected Studies of the Principle of Relative Frequency in Language。1935年出版The Psycho- Biology of Language:An Introduction to Dynamic Philology。1939年被聘为讲师。1949年出版Human Behavior and the Principle of Least Effort:An Introduction to Human Ecology。1950年9月因患癌症病逝。
-
Zipf在1949年的书里提出了一条指导人类行为的基本原则——省力原则。Zipf在序言里指出,如果我们把人类行为纯粹看作一种自然现象,如果我们像研究蜜蜂的社会行为、鸟类的筑巢习惯一样研究人类行为,那么,我们就有可能揭示其背后的基本原则。这是他提出“省力原则”的大背景。当Zipf在众多互不相干的现象里都发现类似Zipf定律的规律性以后,他就开始思考造成这种规律性的原因。这是导致他提出“省力原则”的直接因素。在开始正式论证以前,Zipf首先澄清了“省力原则”的字面意义。
- 第一,这是一种平均量。一个人一生要经历很多事情,他在一件事情上的省力可能导致在另一件事情上的费力。反过来,在一件事情上的费力,又可能导致在另一件事情上的省力。
- 第二,这是一种概率。一个人很难在事先百分之百地肯定某种方法一定能让他省力,他只能有一个大概的估计。因为用词研究是理解整个言语过程的关键,而后者又是理解整个人类生态学的关键,他的具体论证从用词经济开始。Zipf认为,用词经济可以从两个角度来讨论:说话人的角度和听话人的角度。从说话人的角度看,用一个词表达所有的意义是最经济的。这样,说话人不需要花费气力去掌握更多的词汇,也不需要考虑如何从一堆词汇中选择一个合适的词。这种“单一词词汇量”就像木工的一种多用工具,集锯刨钻锤于一身,可以满足多种用途。但是,从听话人角度看,这种“单一词词汇量”是最费力的。他要决定这个词在某个特定场合到底是什么意思,而这几乎是不可能的。相反,对听话人来说,最省力的是每个词都只有一个意义,词汇的形式和意义之间完全一一对应。这两种经济原则是互相冲突、互相矛盾的。Zipf把它们叫做一条言语流中的两股对立的力量:“单一化力量”(the Force of Unification)和“多样化力量”(the Force of Diversification)。他认为,这两股力量只有达成妥协,达成一种平衡,才能实现真正的省力。事实正像预计的那样。请看Zipf的论证:假如只有单一化力量,那么任何语篇的单词数量(number)都会是1,而它的出现次数(frequency)会是100%。另一方面,假如只有多样化力量,那么每个单词的出现次数都会接近1,而单词总数量则由语篇的长度决定。这就是说, number和frequency是衡量词汇平衡程度的两个参数。
中文分词
对于英文而言,由于词自然一般有非常自然的分隔符(空格或标点符号等),因此对于英文而言基本不涉及分词这个任务,而对于中文而言,因为中文没有非常明显的自然分隔符,而且很多自然语言处理任务很大程度上依赖于分词质量,因此中文分词是中文自然语言处理中非常基础且重要的一个任务,以下对中文分词中涉及的基本算法做一个简要的介绍:
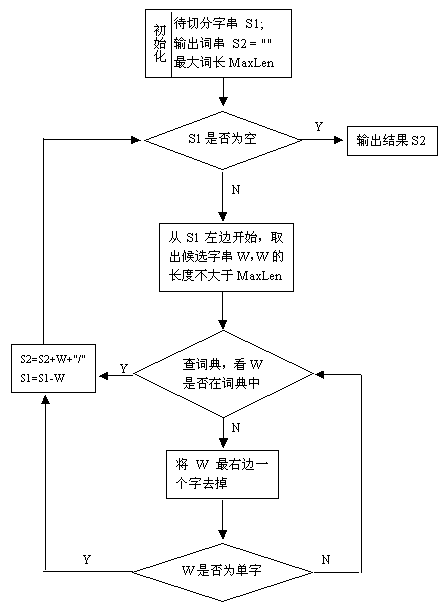
最长正向匹配算法
最长正向匹配算法的基本流程如下图所示:
逆向匹配法思想与正向一样,只是从右向左切分,这里举一个例子:
输入例句:S1=”计算语言学课程有意思”;
定义:最大词长MaxLen = 5;S2="";分隔符="/";
假设存在词表:计算语言学,课程,意思,...;最大逆向匹配分词算法过程如下:
- S2=””;S1不为空,从S1右边取出候选子串W=”课程有意思”;
- 查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有意思”;
- 查词表,W不在词表中,将W最左边一个字去掉,得到W=”有意思”;
- 查词表,W不在词表中,将W最左边一个字去掉,得到W=”意思”
- 查词表,“意思”在词表中,将W加入到S2中,S2=” 意思/”,并将W从S1中去掉,此时S1=”计算语言学课程有”;
- S1不为空,于是从S1左边取出候选子串W=”言学课程有”;
- 查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程有”;
- 查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程有”;
- 查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有”;
- 查词表,W不在词表中,将W最左边一个字去掉,得到W=”有”,这W是单字,将W加入到S2中,S2=“/有/意思”,并将W从S1中去掉,此时S1=”计算语言学课程”;
- S1不为空,于是从S1左边取出候选子串W=”语言学课程”;
- 查词表,W不在词表中,将W最左边一个字去掉,得到W=”言学课程”;
- 查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程”;
- 查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程”;
- 查词表,“意思”在词表中,将W加入到S2中,S2=“ 课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=”计算语言学”;
- S1不为空,于是从S1左边取出候选子串W=”计算语言学”;
- 查词表,“计算语言学”在词表中,将W加入到S2中,S2=“计算语言学/ 课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=””;
- S1为空,输出S2作为分词结果,分词过程结束。
至于怎么实现,中文分词算法之基于词典的正向最大匹配算法一文中对针对JAVA的实现有非常详尽的性能分析,其实吧,个人觉得算法无非是在时间和空间间的权衡,对Hash式存储结构而言,一般来讲,空间开销是很大的,而时间上可以做的很好;对于类似于Trie树的数据结构,在某种程度上能节省一定的空间,但肯定比Hash类数据结构慢点。这里我们就不纠结数据结构和性能的差异了,我们使用STL set1实现上述功能。
以下给出逆向最长匹配算法C++源码(代码中词典的初始化只用了几个词,实际中可从词表文件中读取并构造一个词典,此处代码只是为了演示算法框架):
#include <iostream>
#include <set>
using namespace std;
/**
*A simple inverse match algorithm
*@author:qingyuanxingsi
*@date:2014-05-04
*@version:1.0
*/
int main(int argc, char **argv) {
//Max word length
const int max_len = 5;
const string split_sequence = "/";
const string to_split = "计算语言学真有意思啊";
set<string> dict;
//Initialize the dict
dict.insert("计算语言学");
dict.insert("意思");
//Split the Chinese Sequence
int tail = to_split.length();
for(int i=max_len;i>0&&tail>0;i--){
string temp = to_split.substr(tail-i,i);
//If single word
if(temp.length()==1){
cout<<split_sequence<<temp<<endl;
tail -=1;
if(tail<max_len){
i = tail+1;
}
else{
i = max_len+1;
}
}
if(dict.find(temp)!=dict.end()){
cout<<split_sequence<<temp<<endl;
tail -=i;
if(tail<max_len){
i = tail+1;
}
else{
i = max_len+1;
}
}
}
return 0;
}
NOTE:这种机械的分词方法实际上是远远满足不了我们的需要的,对于某些特定的句子不管采用正向最长匹配还是逆向最长匹配都会产生错误切分。比如说"结婚的和尚未结婚的",采用正向最长匹配就得不到正确的分词结果,逆向最长匹配也类同。类似的分词方法还有最小词数法等。
基于以上简单的中文分词算法,很多学者进行了改进,我爱自然语言网站上介绍了一个叫MMSEG的系统,个人不是很感兴趣,有兴趣的同学可参考如下链接:
基于字标注的中文分词2
以往的分词方法,无论是基于规则的还是基于统计的,一般都依赖于一个事先编制的词表(词典)。自动分词过程就是通过词表和相关信息来做出词语切分的决策。与此相反,基于字标注的分词方法实际上是构词方法。即把分词过程视为字在字串中的标注问题。由于每个字在构造一个特定的词语时都占据着一个确定的构词位置(即词位),假如规定每个字最多只有四个构词位置:即B(词首),M (词中),E(词尾)和S(单独成词),那么下面句子(甲)的分词结果就可以直接表示成如(乙)所示的逐字标注形式:
(甲)分词结果:/上海/计划/N/本/世纪/末/实现/人均/国内/生产/总值/五千美元/。
(乙)字标注形式:上/B 海/E 计/B 划/E N/S 本/s 世/B 纪/E 末/S 实/B 现/E 人/B 均/E 国/B 内/E生/B产/E总/B值/E 五/B千/M 美/M 元/E 。/S
首先需要说明,这里说到的“字”不只限于汉字。考虑到中文真实文本中不可避免地会包含一定数量的非汉字字符,本文所说的“字”,也包括外文字母、阿拉伯数字和标点符号等字符。所有这些字符都是构词的基本单元。当然,汉字依然是这个单元集合中数量最多的一类字符。
把分词过程视为字的标注问题的一个重要优势在于,它能够平衡地看待词表词和未登录词的识别问题。在这种分词技术中,文本中的词表词和未登录词都是用统一的字标注过程来实现的。在学习架构上,既可以不必专门强调词表词信息,也不用专门设计特定的未登录词(如人名、地名、机构名)识别模块。这使得分词系统的设计大大简化。在字标注过程中,所有的字根据预定义的特征进行词位特性的学习,获得一个概率模型。然后,在待分字串上,根据字与字之间的结合紧密程度,得到一个词位的标注结果。最后,根据词位定义直接获得最终的分词结果。总而言之,在这样一个分词过程中,分词成为字重组的简单过程。然而这一简单处理带来的分词结果却是令人满意的。
在《自然语言处理领域的两种创新观念》中,张俊林博士谈了两种创新模式:一种创新是研究模式的颠覆,另外一种创新是应用创新,前者需要NLP领域出现爱因斯坦式的革新人物,后者则是强调用同样的核心技术做不一样的应用。
在自然语言处理领域,多数创新都属于后者,譬如统计机器翻译,Brown就是学习和借鉴了贾里尼克将语音识别看成通信问题的思想,将信源信道模型应用到了机器翻译之中,从而开辟了SMT这一全新领域。而Nianwen Xue将词性标注的思想应用到中文分词领域,成就了字标注的中文分词方法(Chinese Word Segmentation as Character Tagging),同样取得了巨大的成功。
既然基于字标注的中文分词方法是将中文分词当作词性标注的问题来对待,那么就必须有标注对象和标注集了。形象一点,从这个方法的命名上我们就可以推断出它的标注是基本的汉字(还包括一定数量的非汉字字符),而标注集则比较灵活,这些标注集都是依据汉字在汉语词中的位置设计的,最简单的是2-tag,譬如将词首标记设计为B,而将词的其他位置标记设计为I,那么“中国”就可以标记为“中/B 国/I”,“海南岛”则可以标记为“海/B 南/I 岛/I”,相应地,对于如下分好词的句子:
瓦西里斯 的 船只 中 有 40% 驶 向 远东 , 每个 月 几乎 都 有 两三条 船 停靠 中国 港口 。
基于2-tag(B,I)的标注就是:
瓦/B 西/I 里/I 斯/I 的/B 船/B 只/I 中/B 有/B 4/B 0/I %/I 驶/B 向/B 远/B 东/I ,/B 每/B 个/I 月/B 几/B 乎/I 都/B 有/B 两/B 三/I 条/I 船/B 停/B 靠/I 中/B 国/I 港/B 口/I 。/B
除了2-tag,还有4-tag、6-tag等,都是依据字在词中的位置设计的,本文主要目的是从实践的角度介绍基于字标注的中文分词方法设计,以达到抛砖引玉的作用,因此我们仅选用2-tag(B,I)标注集进行实验说明。有了标注对象和标注集,那么又如何进行中文分词呢?因为字标注本质上是采用POS Tagging的思想,只不过要TAG的基本单元现在变成字了而已,因此我们可以这样做:
- 获取已分词语料,将其转化为字的形式并采用某种标注集根据分词信息对其进行标注;
- 将得到的语料作为训练集输入到最大熵模型或者HMM模型中进行训练(可以使用Citar);
- 利用训练后模型对未分词语料进行字标注,最后还原成分词结果即可。
NOTE:利用现有开源工具时,如果能够构建适用于中文字标注的特征集合,然后再进行训练,可能会取得更好的结果。
鲁棒性NLP系统(观点)
一个 real life 自然语言处理系统,其质量和可用度除了传统的 data quality 的衡量指标查准度(precision)和查全度(recall)外,还有更为重要的三大指标:海量处理能力(scalability), 深度(depth)和鲁棒性(robustness)。本部分就简单谈一下鲁棒性。
为了取得语言处理的鲁棒性(robustness),一个行之有效的方法是实现四个形容词的所指:词汇主义(lexicalist); 自底而上(bottom-up); 调适性(adaptive);和数据制导(data-driven)。这四条是相互关联的,但各自重点和视角不同。系统设计和开发上贯彻这四项基本原则, 是取得坚固性的良好保证。有了坚固性,系统对于不同领域的语言,甚至对极不规范的社会媒体中的语言现象,都可以应对。这是很多实用系统的必要条件。
先说词汇主义策略。词汇主义的语言处理策略是学界和业界公认的一个有效的方法。具体说来就是在系统中增加词汇制导的个性规则的总量。自然语言的现象是如此复杂,几乎所有的规则都有例外,词汇制导是必由之路。从坚固性而言,更是如此。基本的事实是,语言现象中的所谓子语言(sublanguage),譬如专业用语,网络用语,青少年用语,他们之间的最大区别是在词汇以及词汇的用法上。一般来说,颗粒度大的普遍语法规则在各子语言中依然有效。因此,采用词汇主义策略,可以有效地解决子语言的分析问题,从而提高系统的鲁棒性。
自底而上的分析方法。这种方法对于自浅而深的管式系统最自然。系统从单词出发,一步一步形成越来越大的句法单位,同时解析句法成分之间的关系。其结果是自动识别(构建)出来的句法结构树。很多人都知道社会媒体的混乱性,这些语言充满了错别字和行话,语法错误也随处可见。错别字和行话由词汇主义策略去对付,语法错误则可以借助自底而上的分析方法。其中的道理就是,即便是充满了语法错误的社会媒体语言,其实并不是说这些不规范的语言完全不受语法规则的束缚,无章可循。事实绝不是如此,否则人也不可理解,达不到语言交流的目的。完全没有语法的“语言”可以想象成一个随机发生器,随机抽取字典或词典的条目发射出来,这样的字串与我们见到的最糟糕的社会媒体用语也是截然不同的。事实上,社会媒体类的不规范语言(degraded text)就好比一个躁动不安的逆反期青年嬉皮士,他们在多数时候是守法的,不过情绪不够稳定,不时会”突破”一下规章法律。具体到语句,其对应的情形就是,每句话里面的多数短语或从句是合法的,可是短语(或从句)之间常常会断了链子。这种情形对于自底而上的系统,并不构成大的威胁。因为系统会尽其所能,一步一步组合可以预测(解构)的短语和从句,直到断链的所在。这样一来,一个句子可能形成几个小的句法子树(sub-tree),子树之内的关系是明确的。朋友会问:既然有断链,既然子树没有形成一个完整的句法树来涵盖所分析的语句,就不能说系统真正鲁棒了,自然语言理解就有缺陷。抽象地说,这话不错。但是在实际使用中,问题远远不是想象的那样严重。其道理就是,语言分析并非目标,语言分析只是实现目标的一个手段和基础。对于多数应用型自然语言系统来说,目标是信息抽取(Information Extraction),是这些预先定义的抽取目标在支持应用(app)。抽取模块的屁股通常坐在分析的结构之上,典型的抽取规则 by nature 是基于子树匹配的,这是因为语句可以是繁复的,但是抽取的目标相对单纯,对于与目标不相关的结构,匹配规则无需cover。这样的子树匹配分两种情形,其一是抽取子树(subtree1)的规则完全匹配在语句分析的子树(subtree2)之内(i.e. subtree2 > subtree1),这种匹配不受断链的任何影响,因此最终抽取目标的质量不受损失。只有第二种情形,即抽取子树恰好坐落在分析语句的断链上,抽取不能完成,因而印象了抽取质量。值得强调的是,一般来说,情形2的出现概率远低于情形1,因此自底而上的分析基本保证了语言结构分析的鲁棒性,从而保障了最终目标信息抽取的达成。其实,对于 worst case scenario 的情形2,我们也不是没有办法补救。补救的办法就是在分析的后期把断链 patch 起来,虽然系统无法确知断链的句法关系的性质,但是patched过的断链形成了一个完整的句法树,为抽取模块的补救创造了条件。此话怎讲?具体说来就是,只要系统的设计和开发者坚持调适性开发抽取模块(adaptive extraction)的原则,部分抽取子树的规则完全可以建立在被patched的断链之上,从而在不规范的语句中达成抽取。其中的奥妙就是某样榜戏中所说的墙内损失墙外补,用到这里就是结构不足词汇补。展开来说就是,任何子树匹配不外乎check两种条件约束,一是节点之间的关系句法关系的条件(主谓,动宾,等等),另外就是节点本身的词汇条件(产品,组织,人,动物,等等)。这些抽取条件可以相互补充,句法关系的条件限制紧了,节点词汇的条件就可以放宽;反之亦然。即便对于完全合法规范的语句,由于语言分析器不可避免的缺陷而可能导致的断链(世界上除了上帝以外不存在完美的系统),以及词汇语义的模糊性,开发者为了兼顾查准率和查全率,也会在抽取子树的规则上有意平衡节点词汇的条件和句法关系的条件。如果预知系统要用于不规范的语言现象上,那么我们完全可以特制一些规则,利用强化词汇节点的条件来放宽对于节点句法关系的条件约束。其结果就是适调了patched的断链,依然达成抽取。说了一箩筐,总而言之,言而总之,对于语法不规范的语言现象,自底而上的分析策略是非常有效的,加上调适性开发,可以保证最终的抽取目标基本不受影响。
调适性上面已经提到,作为一个管式系统的开发原则,这一条很重要,它是克服错误放大(error propagation)的反制。理想化的系统,模块之间的接口是单纯明确的,铁路警察,各管一段,步步推进,天衣无缝。但是实际的系统,特别是自然语言系统,情况很不一样,良莠不齐,正误夹杂,后面的模块必须设计到有足够的容错能力,针对可能的偏差做调适才不至于一错再错,步步惊心。如果错误是consistent/predictable 的,后面的模块可以矫枉过正,以毒攻毒,错错为正。还有一点就是歧义的保存(keeping ambiguity untouched)策略。很多时候,前面的模块往往条件不成熟,这时候尽可能保持歧义,运用系统内部的调适性开发在后面的模块处理歧义,往往是有效的。
最后,数据制导的开发原则,怎样强调都不过分。语言海洋无边无涯,多数语言学家好像一个爱玩水的孩子,跳进海洋往往坐井观天,乐不思蜀。见树木不见森林,一条路走到黑,是很多语言学家的天生缺陷。如果由着他们的性子来,系统的overhead越来越大,效果可能越来越小。数据制导是迫使语言学家回到现实,开发真正有现实和统计意义的系统的一个保证。这样的保证应该制度化,这牵涉到开发语料库(dev corpus)的选取,baseline 的建立和维护,unit testing 和regression testing 等开发操作规范的制定以及 data quality QA 的配合。理想的数据制导还应该包括引入机器学习的方法,来筛选制约具有统计意义的语言现象反馈给语言学家。从稍微长远一点看,自动分类用户的数据反馈,实现某种程度的粗颗粒度的自学习,建立半自动人际交互式开发环境,这是手工开发和机器学习以长补短的很有意义的思路。以上所述,每一条都是经验的总结,背后有成百上千的实例可以详加解说。不过,网文也不是科普投稿,没时间去细细具体解说了。做过的自然有同感和呼应,没做过的也许不明白,等做几年就自然明白了,又不是高精尖的火箭技术。
无约束最优化
看了一下我爱自然语言处理博客上关于无约束优化的几篇文章,可能是自己水平很烂的原因,感觉怪怪的,好像有点不对劲,还是自己查相关资料吧。以下给出那几篇的链接.
资源集锦
- ACL Anthology Network
- LDC (Linguistic Data Consortium)
- Microsoft N-gram Service
- Start Question-Answering System;
TODO Board:
- TBL(参考《自然语言处理综论》第8章)
- 最大熵求解算法IIS等
- 1-Gram Python分词实现;之后自己实现一个3-gram Language Model吧!
- Topic modeling made just simple enough
- STL中set的简单学习 ↩
- 本部分更多细节请参考我爱自然语言处理博客! ↩