机器学习系列(VII):Kernels
这一篇作为机器学习系列的第七篇,主要介绍核方法,关于SVM的部分Pluskid已经写的很通俗易懂了,具体请参考小小收藏夹[持续更新中]中SVM部分的链接,本文主要补充关于核方法的一些其他知识吧。
我们之前介绍的所有方法均假定Object可被恰当地表示为一定长的特征向量$x_i \in R^D$.然而,对于某些情况而言,我们也许并不知道如何将它们表示成定长的特征向量。如,我们如何表示可变长的文本文档或者蛋白质序列?如何表示具有复杂3D结构的分子结构?如何表示具有可变大小和形状的进化树?
解决以上问题的方法之一是为数据定义一生成模型,并使用推断得到的隐含表示作为特征输入到标准的方法中,如Deep Learning.另一方法则是我们假定我们有某种方法能够衡量Objects之间的相似度,因此我们并不需要将数据预处理为特征向量的形式。如当我们比较字符串时,我们可以计算它们之间的编辑距离。令$k(x,x\prime) \geq 0$作为衡量$x$和$x\prime$之间差异性的某种标准($k$被称为核函数Kernel Function).以下我们介绍几种常见的核函数。
核函数
我们将核函数定义为:$k(x,x\prime) \in R$,即将两参数$x,x\prime \in X$($X$为某抽象空间)映射为一实数值。一般而言,它具有对称性,即$k(x,x\prime) = k(x\prime,x)$和非负性,即$k(x,x\prime) \geq 0$.以下我们给出几个例子:
RBF Kernels
Squared exponential kernel(SE kernel)或高斯核(Gaussian kernel)定义如下:
\begin{equation} k(x,x\prime) = exp(-{1 \over 2}(x-x\prime)^T\Sigma^{-1}(x-x\prime)) \end{equation}
若$\Sigma$是对角阵,则有:
\begin{equation} k(x,x\prime) = exp(-{1 \over 2}\sum_{j=1}^D \frac{1}{\sigma_j^2}(x_j-x_j\prime)^2) \end{equation}
我们可将$\sigma_j$理解为对于维度$j$的Characteristic length scale.若$\sigma_j = \infty$,则相应的维度可被忽略掉,此时则称其为ARD kernel.若$\Sigma$呈球面分布,我们则得到:
\begin{equation} k(x,x\prime) = exp(-\frac{||x-x\prime||^2}{2\sigma^2}) \end{equation}
其中,$\sigma^2$被称为带宽(Bandwith).上式为径向基核的一个例子(它只是$||x-x\prime||$的函数)。
文档核
当我们想要进行文档分类时,如果有一种方法能够比较文档$x_i$和$x_i\prime$想必是极好的。如果我们采用bag-of-words表示且令$x_{ij}$表示词$j$在文档$i$中出现的次数,我们可以采用余弦距离,定义为:
\begin{equation} k(x_i,x_i\prime) = \frac{x_i^T x_i \prime}{||x_i||_2 ||x_i \prime||_2} \end{equation}
然而这种方法并不好,主要缺点有如下两点:
- 文档中可能包含一些停用词(无实际意义的词,如
the,and等),它们本身不能用于判断两个文档的相似度,而在上述计算中被包含在内了; - 如果一个词能被用于判断两个文档之间的相似度,那么如果它在一个文档中出现多次,则我们人为地提高了两个文档的相似度.
幸运的是,我们通过简单的预处理就能大幅提升性能---我们将词频统计向量替换为词频-倒排文档频率TF-IDF.我们首先作如下定义:
我们将词频定义为(减少由于一个词在文档中出现多次造成的影响):
\begin{equation} tf(x_{ij}) \triangleq log(1+x_{ij}) \end{equation}
我们将倒排文档频率定义为:
\begin{equation} idf(j) \triangleq log \frac{N}{1+\sum_{i=1}^N 1_{x_{ij} > 0}} \end{equation}
其中,$N$表示文档总数,分母则计算包含$j$的文档总数。
最后,我们定义:
\begin{equation} tf-idf(x_i) \triangleq [tf(x_{ij} \times idf(j)]_{j=1}^V \end{equation}
我们将上式带入余弦距离即可。于是我们得到Kernel:
\begin{equation} k(x_i,x_i\prime) = \frac{\phi(x_i)^T\phi(x_i\prime)}{||\phi(x_i)||_2||\phi(x_i\prime)||_2} \end{equation}
其中,$\phi(x) = tf-idf(x)$.
Mercer(positive definite) kernels
某些方法要求Gram matrix对于任意输入集合${x_i}_{i=1}^N$均是正定的,这样的核称为Mercer kercel或正定核。我们1可以证明以上提到的高斯核以及文档核均是Mercel kernel.Gram matrix定义为:
\begin{equation} K = \left( \begin{array}{cc} k(x_1,x_1) & \ldots & k(x_1,x_N) \\ & \vdots & \\ k(x_N,x_1) & \ldots & k(x_N,x_N) \end{array} \right) \end{equation}
Mercer's Theorem
若Gram矩阵是正定的,则我们可作如下特征值分解:
\begin{equation} K = U^T\Lambda U \end{equation}
其中$\Lambda$是特征值均大于0的对角阵。现我们考虑$K$中的一个元素,有:
\begin{equation} k_{ij} = (\Lambda^{1 \over 2}U_{:,i})^T(\Lambda^{1 \over 2}U_{:,j}) \end{equation}
令$\phi(x_i) = \Lambda^{1 \over 2}U_{:,i}$,我们有:
\begin{equation} k_{ij} = \phi(x_i)^T \phi(x_j) \end{equation}
我们可以看到核矩阵的每一项可通过对特征向量作内积得到,而特征向量可由矩阵分解得到的特征向量$U$定义。一般地,如果kernel是Mercer Kernel,那么就存在一个从$x \in X$到$R^D$的映射$\phi$,使得:
\begin{equation} k(x,x\prime) = \phi(x)^T \phi(x\prime) \end{equation}
比如,我们考察多项式核$k(x,x\prime) = (\gamma x^Tx\prime+r)^M$,其中$r>0$.我们可以证明$\phi(x)$将包含到$M$的所有项。例如,若我们取$M=2,\gamma = r = 1$且$x,x\prime \in R^2$,我们则有:
\begin{equation} \begin{split} (1+x^Tx\prime)^2 &= (1+x_1x_1\prime+x_2x_2\prime)^2 \\ &= 1+2x_1x_1\prime+2x_2x_2\prime+(x_1x_1\prime)^2+(x_2x_2\prime)^2+2x_1x_1\prime x_2x_2\prime \end{split} \end{equation}
此时我们有:
\begin{equation} \phi(x) = [1,\sqrt{2}x_1,\sqrt{2}x_2,x_1^2,x_2^2,\sqrt{2}x_1x_2]^T \end{equation}
因此采用该kernel等同于在6维空间内进行计算。对于Gaussian核而言,映射后则是在无穷维空间内。在这种情形下,显式表示特征向量显然是不可行的。
Linear Kernels
根据Kernel推导出特征向量是非常困难的一件事(仅当Kernel为Mercer时才可行),然而有特征向量推导出Kernel则容易的多。
\begin{equation} k(x,x\prime) = \phi(x)^T \phi(x\prime) = <\phi(x),\phi(x\prime)> \end{equation}
如果$\phi(x)=x$,我们得到线性核,定义为:
\begin{equation} k(x,x\prime) = x^Tx\prime \end{equation}
其实也就是在原空间内进行计算。
Matern kernels
Matern Kernels通常被用于高斯过程回归,并被定位为:
\begin{equation} k(r) = \frac{2^{1-\nu}}{\Gamma(\nu)}(\frac{\sqrt{2\nu}r}{\ell})^{\nu}K_{\nu}(\frac{\sqrt{2\nu}r}{\ell}) \end{equation}
其中,$r=||x-x\prime||,\nu>0,\ell>0$且$K_{\nu}$为修改后的Bessel函数。当$\nu \to \infty$时,它趋近于高斯核。若$\nu ={1 \over 2}$,它简化为:
\begin{equation} k(r) = exp(-r/\ell) \end{equation}
若$D=1$,我们可以使用该核定义一高斯过程,我们得到Ornstein-Uhlenbeck process,它刻画了一个正在做布朗运动的例子的速度.
字符串核
当输入项为结构化数据时,核方法才能真正发挥其威力。以下我们举一个例子简要说明一下多项式核。考察两个字符串长度分别为$D$和$D\prime的定义在符号表${A,R,N,D,C,E,Q,G,H,I,L,K,M,F,P,S,T,W,Y,V}$上的字符串$$x$和$x\prime$.令$x$为一长度为110的字符串,如下图所示:
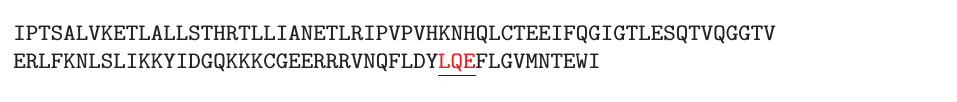
$x\prime$为长度为153的字符串。
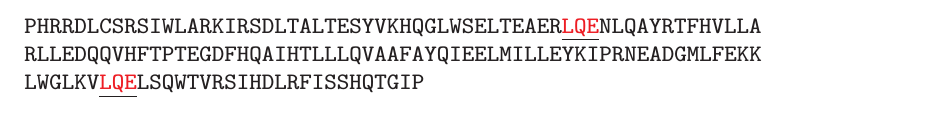
两个字符串均包含$LQE$,如上图琐事。我们可以将两个字符串的相似度定义为它们共同包含的字串的数量。正式地,若$x = usv$,则我们可以说$s$是$x$的字串.令$\phi_s(x)$表示字串$s$在字符串$x$中出现的次数。因此字符串核可定义为:
\begin{equation} k(x,x\prime) = \sum_{s \in A*} w_s \phi_s(x) \phi_s(x\prime) \end{equation}
其中,$w_s \geq 0$且$A*$表示由字符表$A$所能生成的所有字符串。它是Mercer Kernel且可在$O(|x|+|x\prime|)$时间内计算得到。
NOTE:Why $O(|x|+|x\prime|)$,求大神解答。
有了上式之后,我们就能"为所欲为"了。若当$|s|>1$时我们令$w_s = 0$,那么我们得到一bag-of-characters核,此时$\phi(x)$表示$A$中每个字符在$x$中出现的次数;如果我们采用空格分隔$s$,我们得到一bag-of-words核,其中$\phi(x)$表示每个词在$x$中出现的次数。
Kernels derived from probabilistic models
假定我们有一生成概率模型$p(x|\theta)$.那么我们有多种方法可以通过它构造核函数,以使模型更适用于判别类人物。以下我们简要介绍两种方法:
Probability product models
方法之一是定义如下Kernel:
\begin{equation} k(x_i,x_j) = \int p(x|x_i)^{\rho}p(x|x_j)^{\rho} dx \end{equation}
其中$\rho>0$,且$p(x|x_i)$一般通过计算$p(x|\hat{\theta}(x_i))$来近似,其中$\hat{\theta}(x_i)$是通过计算单一数据向量得到的对于参数的估计值。上式被称为Probability product kernel.
尽管使用单一数据点估计参数显得很诡异,然后我们需要注意的是它仅被用于衡量两个Objects之间的相似度。特别地,如果我们采用$x_i$进行估计而得到的模型认为$x_j$是很有可能得到的,则证明$x_i$和$x_j$是相似的。如我们假定$p(x|\theta) = N(\mu,\sigma^2I)$,其中$\sigma^2$是定值。若$\rho = 1$,且我们令$\hat{\mu}(x_i) = x_i$和$\hat{\mu}(x_j) = x_j$,我们得到:
\begin{equation} k(x_i,x_j) = \frac{1}{(4\pi\sigma^2)^{D/2}}exp(-\frac{1}{4\sigma^2}||x_i-x_j||^2) \end{equation}
即RBF Kernel.
Fisher kernels
另一更为有效的通过生成模型定义Kernel的方法是采用Fisher kernel.定义如下:
\begin{equation} k(x,x\prime) = g(x)^T F^{-1} g(x\prime) \end{equation}
其中,$g$是对数似然函数梯度或score vector在极大似然估计处的取值。
\begin{equation} g(x) = \bigtriangledown_{\theta} log p(x|\theta)|{\hat{\theta}} \end{equation}
$F$为Fisher information matrix,即Hessian.
\begin{equation} F = \bigtriangledown \bigtriangledown log p(x|\theta)|{\hat{\theta}} \end{equation}
注意$\hat{\theta}$为所有数据的函数,因此$x$和$x\prime$之间的相似度的计算也是将所有数据考虑在内的,所以我们只需要Fit一次Model.
该模型背后的Intuition是如果它们的方向梯度是相似的话,则两个向量也是相似的。(好吧,其实这个也不是弄得灰常清楚啦,TAT)
TODO Board:
- 后缀树Suffix Tree