PREFACE
在上一篇分布式计算与存储系列(序章):初入门径中,我们主要介绍了分布式存储的一些基础知识,在本系列中,我们会结合论文以及源码对分布式计算的基本理论以及一些应用系统进行研究,以期对分布式系统有一个更为深入的了解。本系列的前若干篇均以研究Yarn为主,主要参考Hadoop技术内幕:深入解析YARN架构设计与实现原理一书的整体架构,但是个人对这本书不是特别满意,讲述的还是有点浅,很多问题只是浅尝则止而已。(真正想深入了解YARN的不建议购买此书,如若只是想粗略的了解一下YARN的工作流程的童鞋倒是可以入手一本滴。)因此,本系列仅会采用其大体框架,在其大体框架下,对YARN设计的其他知识和设计模式等也会有进一步更为深入的介绍。好吧,闲话就不多说了,我们开始正式讨论。
本文的主要目的是介绍一下YARN中用到的基础库,它们是YARN其他模块得以建立的基石,其重要性自然不言而喻。我们先从其RPC库说起。
The Secret of RPC
当前存在非常多的开源 RPC 框架,比较有名的有 Thrift、Protocol Buffers 和 Avro。同Hadoop RPC一样,它们均由两部分组成:对象序列化和远程过程调用(Protocol Buflers官方仅提供了序列化实现,未提供远程调用相关实现,但三方 RPC 库非常多 )。相比于Hadoop RPC,它们有以下几个特点:
- 跨语言特性。对于 Hadoop RPC而言,由于Hadoop采用 Java 语言编写,因而其RPC客户端和服务器端仅支持Java语言;但对于更通用的 RPC框架,如Thrift或者Protocol Buffers等,其客户端和服务器端可采用任何语言编写,如Java、C++、Python等,这给用户编程带来极大方便。
- 引入IDL。开源RPC框架均提供了一套接口描述语言(Interface Description Language,IDL),它提供一套通用的数据类型,并以这些数据类型来定义更为复杂的数据类型和对外服务接口。一旦用户按照IDL定义的语法编写完接口文件后,可根据实际应用需要生成特定编程语言(如 Java、C++、Python 等)的客户端和服务器端代码。
- 协议兼容性。开源RPC框架在设计上均考虑到了协议兼容性问题,即当协议格式发生改变时,比如某个类需要添加或者删除一个成员变量(字段)后,旧版本代码仍然能识别新格式的数据,也就是说,具有向后兼容性。
随着Hadoop版本的不断演化,研发人员发现Hadoop RPC在跨语言支持和协议兼容性两个方面存在不足,具体表现为:
- 从长远发展看,Hadoop RPC应允许某些协议的客户端或者服务器端采用其他语言实现,比如用户希望直接使用C/C++语言读写HDFS中的文件,这就需要有C/C++语言的HDFS客户端。
- 当前 Hadoop 版本较多,而不同版本之间不能通信,比如0.20.2版本的JobTracker不能与0.21.0版本中的TaskTracker通信,如果用户企图这样做,会抛出VersionMismatch异常。
为了解决以上几个问题,Hadoop YARN将RPC中的序列化部分剥离开,以便将现有的开源RPC框架集成进来。Hadoop目前集成了Protocol Buffer以及Apache Avro的序列化部分,而函数调用调用机制仍采用Hadoop自带的,其中RPC采用Protocol Buffer,而Apache Avro则用于日志系统。以下对这两种序列化机制进行一个简要的介绍:
持久化框架
Protocol Buffer1
Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据序列化/反序列化。它很适合做数据存储或RPC的数据交换格式,常用作通信协议、数据存储等领域的与语言无关、平台无关、可扩展的序列化结构数据格式。目前支持C++、Java、Python三种语言。在 Google 内部,几乎所有的RPC协议和文件格式都是采用Protocol Buffers。
相比于常见的XML格式,Protocol Buffers官方网站这样描述它的优点:
- 平台无关、语言无关;
- 高性能,解析速度是 XML 的 20 ~ 100 倍;
- 体积小,文件大小仅是 XML 的 1/10 ~ 1/3;
- 使用简单;
- 兼容性好。
通常编写一个 Protocol Buffers 应用需要以下三步:
- 定义报文格式(.proto文件)
- 使用Protocol Buffer Compiler编译生成JAVA类
- 使用Protocol Buffer API读写报文
定义报文格式
我们首先定义消息格式文件addressbook.proto,以下定义了一个人的通讯录的基本信息:
package tutorial;
option java_package = "com.qingyuanxingsi.tutorial";
option java_outer_classname = "AddressBookProtos";
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
message AddressBook {
repeated Person person = 1;
}
.proto文件开头包含一个包声明,以避免不同Project之间的命名冲突。Java中,package名即被用作Java包名,除非通过java_package另外显式指定表明。以上我们制定生成的包名为com.qingyuanxingsi.tutorial.java_outer_classname则指定了类名,我们生成的所有类均会被放在这个文件中。如果未显式制定,则会将文件名自动转化成Camel形式的类名。如,my_proto.proto默认情况下会生成MyProto作为其类名。
接下来则是报文定义。一个报文即是一系列带有类型信息的Field的集合。很多简单数据类型可被用作Field Type,包括bool, int32, float, double, and string. 当然,你也可以自定义类型作为Field Type.在上述例子中,Person报文就包含PhoneNumber报文,AddressBook报文则包括Person报文。另外,报文可被嵌套定义,如PhoneNumber就定义在Person报文中。如果你想让你的某个Field具有一个或多个预定义的值,你可以使用枚举类型,如上述,我们想让电话号码类型取MOBILE, HOME, or WORK中的值。每个字段后的=?标记为每个Field分配了唯一的TAG,以用于二进制编码。
required关键字指定该Field必须被赋值,否则报文将会被视为uninitialized.编译此类报文则会抛出RuntimeException异常,除此之外,它与optional field基本相同。optional关键字则表明该Field可被设置,也可不设置。如果未设置,则会使用默认值。对于简单数据类型,我们可以定义我们自己的默认值,否则则会使用系统默认值。对于嵌套报文,默认值则通常会是报文的默认实例或者原型,其中每一个Field均未被设置。repeated则表明该字段可以重复任何多次。
编译生成JAVA类
使用以下命令即可生成相应的JAVA类:
protoc -I=$SRC_DIR --java_out=$DST_DIR $SRC_DIR/addressbook.proto
生成的类的结构如下图所示(此处不再给出源码):
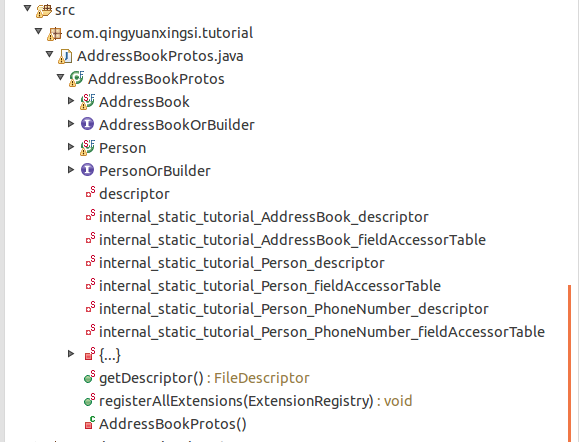
使用Protocol Buffer API读写报文
如上图所示,我们可以看到一个AddressBookProtos.java类,其中则嵌套了多个类,每个类均有.proto中定义的message生成。每个类都有对应的一个Builder类,可以用于构造类实例。
报文类以及Builder类对于报文的每个Field均提供了访问器。值得注意的是,报文类仅提供了getters,而Builder类既有getters,又有setters.以下给出Person类的一个实例:
// required string name = 1;
public boolean hasName();
public String getName();
// required int32 id = 2;
public boolean hasId();
public int getId();
// optional string email = 3;
public boolean hasEmail();
public String getEmail();
// repeated .tutorial.Person.PhoneNumber phone = 4;
public List<PhoneNumber> getPhoneList();
public int getPhoneCount();
public PhoneNumber getPhone(int index);
而与其对应的Builder类则getters和setters都有:
// required string name = 1;
public boolean hasName();
public java.lang.String getName();
public Builder setName(String value);
public Builder clearName();
// required int32 id = 2;
public boolean hasId();
public int getId();
public Builder setId(int value);
public Builder clearId();
// optional string email = 3;
public boolean hasEmail();
public String getEmail();
public Builder setEmail(String value);
public Builder clearEmail();
// repeated .tutorial.Person.PhoneNumber phone = 4;
public List<PhoneNumber> getPhoneList();
public int getPhoneCount();
public PhoneNumber getPhone(int index);
public Builder setPhone(int index, PhoneNumber value);
public Builder addPhone(PhoneNumber value);
public Builder addAllPhone(Iterable<PhoneNumber> value);
public Builder clearPhone();
由Protocol Buffer Compiler编译生成的message类均是不可变的。Message实例一旦生成,就不能更改。为了构造一个message,我们首先构造一个builder,将Field设置成你想要的值,然后调用builder的build()方法。以下代码用于构造一个Person实例:
Person john =
Person.newBuilder()
.setId(1234)
.setName("John Doe")
.setEmail("jdoe@example.com")
.addPhone(
Person.PhoneNumber.newBuilder()
.setNumber("555-4321")
.setType(Person.PhoneType.HOME))
.build();
最后,每个Protocol Buffer类军定义了读写报文的方法,如下所示:
- byte[] toByteArray();持久化message对象并返回包含一字节数组。
- static Person parseFrom(byte[] data);通过给定字节数组解析构造报文实例。
- void writeTo(OutputStream output);将报文持久化到OutputStream中.
- static Person parseFrom(InputStream input);解析InputStream并构造报文实例.
至此,我们给出一个报文读写实例,它用于将报文持久化到文件中然后从文件中解析构造得到原始报文:
package org.qingyuanxingsi.protoc;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import com.qingyuanxingsi.tutorial.AddressBookProtos.AddressBook;
import com.qingyuanxingsi.tutorial.AddressBookProtos.Person;
import com.qingyuanxingsi.tutorial.AddressBookProtos.Person.PhoneNumber;
import com.qingyuanxingsi.tutorial.AddressBookProtos.Person.PhoneType;
/**
* A toy example demonstrates the writing and reading process to an address book
* proto.
*
* @author qingyuanxingsi
*
*/
public class AddressBookDemo {
private static final String FILE_PATH = "addressbook.dat";
public static void main(String[] args) {
// TODO Auto-generated method stub
addPerson();
printData();
}
/**
* Print the data out
*/
public static void printData() {
// TODO Auto-generated method stub
try {
AddressBook addressBook = AddressBook
.parseFrom(new FileInputStream(new File(FILE_PATH)));
print(addressBook);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* Print the whole all data
*
* @param addressBook
*/
public static void print(AddressBook addressBook) {
// TODO Auto-generated method stub
//Iterate over the address book
for (Person person : addressBook.getPersonList()) {
System.out.println("Person ID: " + person.getId());
System.out.println("Person Name: " + person.getName());
if (person.hasEmail()) {
System.out.println("E-mail address: " + person.getEmail());
}
//Get phone numbers
for (Person.PhoneNumber phoneNumber : person.getPhoneList()) {
switch (phoneNumber.getType()) {
case MOBILE:
System.out.print("Mobile phone #: ");
break;
case HOME:
System.out.print("Home phone #: ");
break;
case WORK:
System.out.print("Work phone #: ");
break;
}
System.out.println(phoneNumber.getNumber());
}
}
}
/**
* Add a person to the address book file
*/
public static void addPerson() {
// TODO Auto-generated method stub
Person person = Person
.newBuilder()
.setId(1)
.setName("qingyuanxingsi")
.setEmail("demo@server.com")
.addPhone(
PhoneNumber.newBuilder().setNumber("13456723421")
.setType(PhoneType.MOBILE).build()).build();
AddressBook addressBook = AddressBook.newBuilder().addPerson(person)
.build();
// System.out.println(person);
FileOutputStream outputStream;
try {
outputStream = new FileOutputStream(new File(FILE_PATH));
addressBook.writeTo(outputStream);
outputStream.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
Apache Avro2
Apache Avro 是Hadoop 下的一个子项目。它本身既是一个序列化框架,同时也实现了RPC 的功能。Avro官网描述Avro的特性和功能如下:
- 丰富的数据结构类型;
- 快速可压缩的二进制数据形式;
- 存储持久数据的文件容器;
- 提供远程过程调用 RPC;
- 简单的动态语言结合功能。
相比于Apache Thrift和Google Protocol Buffers,Apache Avro具有以下特点:
- 支持动态模式 。Avro 不需要生成代码,这有利于搭建通用的数据处理系统,同时避免了代码入侵。
- 数据无须加标签 。读取数据前,Avro能够获取模式定义,这使得Avro在数据编码时只需要保留更少的类型信息,有利于减少序列化后的数据大小。
- 无须手工分配的域标识。Thrift 和 Protocol Buffers使用一个用户添加的整型域唯一性定义一个字段,而Avro则直接使用域名,该方法更加直观、更加易扩展。
编写一个 Avro 应用也需如下三步:
- 定义消息格式文件,通常以 avro 作为扩展名;
- 使用Avro编译器生成特定语言的代码文件(可选);
- 使用Avro库提供的 API 来编写应用程序。
定义消息格式文件
Avro schema是用JSON定义的。它有基本数据类型(null, boolean, int, long, float, double, bytes, string)以及复合数据类型(record, enum, array, map, union, and fixed)组成。以下给出一个具体实例user.avsc:
{"namespace": "example.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
Compiling the schema(Optional)
同Protocol Buffer一样,Apache Avro可以根据Scheme定义自动生成JAVA类。我们可以通过avro-tools工具生成相应的类:
java -jar /path/to/avro-tools-1.7.6.jar compile schema <schema file> <destination>
就我们的例子而言,可以通过如下命令生成对应的JAVA类:
java -jar /path/to/avro-tools-1.7.6.jar compile schema user.avsc
生成的类结构如下图所示:

序列化与反序列化
当我们直接使用生成的JAVA类时,可通过如下方法持久化一个User:
// Serialize user user1 to disk
File file = new File("user.avro");
DatumWriter<User> userDatumWriter = new SpecificDatumWriter<User>(User.class);
DataFileWriter<User> dataFileWriter = new DataFileWriter<User>(userDatumWriter);
dataFileWriter.create(user1.getSchema(), new File("users.avro"));
dataFileWriter.append(user1);
dataFileWriter.close();
我们首先创建一个DatumWriter, 它负责将JAVA对象转化成内存中的序列化格式;SpecificDatumWriter类则与具体的生成类相关并从指定类中抽取Schema定义信息。 然后我们创建一个DataFileWriter,它将内存中的持久化对象以及Schema定义持久化到文件中。 最后,我们通过其append方法添加一个User实例。
当我们要反序列化时,则可以使用如下方法:
// Deserialize Users from disk
DatumReader<User> userDatumReader = new SpecificDatumReader<User>(User.class);
DataFileReader<User> dataFileReader = new DataFileReader<User>(file, userDatumReader);
User user = null;
while (dataFileReader.hasNext()) {
// Reuse user object by passing it to next(). This saves us from
// allocating and garbage collecting many objects for files with
// many items.
user = dataFileReader.next(user);
System.out.println(user);
}
反序列化与序列化基本相同,我们首先创建一个SpecificDatumReader,它将内存中的对象反序列化为我们的User实例,我们将DatumReader以及之前创建的文件传给DataFileReader,它从文件中读取信息。接着我们使用DataFileReader遍历已经序列化的User然后将反序列化之后的信息打印到标准输出流。
当然,正如我们上述介绍Avro的特性时提到的那样,其实Avro可以不必生成对应的JAVA类,也就是说我们可以仅依靠Scheme定义直接序列化、反序列化对象。
我们可以通过如下方法创建User实例:
//Read Scheme definition and create a Schema object
Schema schema = new Parser().parse(new File("user.avsc"));
//Create user using above Schema
GenericRecord user1 = new GenericData.Record(schema);
user1.put("name", "Alyssa");
user1.put("favorite_number", 256);
// Leave favorite color null
GenericRecord user2 = new GenericData.Record(schema);
user2.put("name", "Ben");
user2.put("favorite_number", 7);
user2.put("favorite_color", "red");
接着,我们可以以如下方式序列化User实例:
// Serialize user1 and user2 to disk
File file = new File("users.avro");
DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(datumWriter);
dataFileWriter.create(schema, file);
dataFileWriter.append(user1);
dataFileWriter.append(user2);
dataFileWriter.close();
以上序列化过程基本和使用Code Generation时相同。
最后,我们反序列化如上对象,当然,和之前Code Generation时也类似:
// Deserialize users from disk
DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(file, datumReader);
GenericRecord user = null;
while (dataFileReader.hasNext()) {
// Reuse user object by passing it to next(). This saves us from
// allocating and garbage collecting many objects for files with
// many items.
user = dataFileReader.next(user);
System.out.println(user);
以下给出一完整实例:
package org.qingyuanxingsi.avrodemo;
import java.io.File;
import java.io.IOException;
import org.apache.avro.Schema;
import org.apache.avro.Schema.Parser;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumReader;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumReader;
import org.apache.avro.specific.SpecificDatumWriter;
import example.avro.User;
/**
* A toy example demonstrates the use of Apache Avro
*
* @author qingyuanxingsi
* @version 1.0
*/
public class AvroDemo {
// File Path storing demo data
private static final String FILE_PATH = "user.dat";
/**
* Test Case
*
* @param args
*/
public static void main(String[] args) {
//Avro with code generation
avroWithCode();
//Avro without code generation
avroWithoutCode();
}
/**
* Avro without code generation
*/
private static void avroWithoutCode() {
// TODO Auto-generated method stub
System.out.println("-----------------------------");
System.out.println("2.Avro without code generation!");
System.out.println("-----------------------------");
Parser parser = new Parser();
try {
Schema schema = parser.parse(new File("user.avsc"));
GenericRecord user = new GenericData.Record(schema);
user.put("name", "qingyuanxingsi");
user.put("favorite_number", 6);
user.put("favorite_color", "BLUE");
// Serialize it
File file = new File(FILE_PATH);
DatumWriter<GenericRecord> userDatumWriter = new SpecificDatumWriter<GenericRecord>(
schema);
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(
userDatumWriter);
try {
dataFileWriter.create(schema, file);
dataFileWriter.append(user);
dataFileWriter.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// Deserialize Users from disk
DatumReader<GenericRecord> userDatumReader = new SpecificDatumReader<GenericRecord>(
schema);
DataFileReader<GenericRecord> dataFileReader;
try {
dataFileReader = new DataFileReader<GenericRecord>(file, userDatumReader);
GenericRecord tmp = null;
while (dataFileReader.hasNext()) {
// Reuse user object by passing it to next(). This saves us from
// allocating and garbage collecting many objects for files with
// many items.
tmp = dataFileReader.next(tmp);
System.out.println(tmp);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* Avro with code generation
*/
private static void avroWithCode() {
// TODO Auto-generated method stub
System.out.println("-----------------------------");
System.out.println("1.Avro with code generation!");
System.out.println("-----------------------------");
User user = User.newBuilder().setName("qingyuanxingsi")
.setFavoriteNumber(5).setFavoriteColor("PURPLE").build();
// Serialize it
File file = new File(FILE_PATH);
DatumWriter<User> userDatumWriter = new SpecificDatumWriter<User>(
User.class);
DataFileWriter<User> dataFileWriter = new DataFileWriter<User>(
userDatumWriter);
try {
dataFileWriter.create(user.getSchema(), file);
dataFileWriter.append(user);
dataFileWriter.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// Deserialize Users from disk
DatumReader<User> userDatumReader = new SpecificDatumReader<User>(
User.class);
DataFileReader<User> dataFileReader;
try {
dataFileReader = new DataFileReader<User>(file, userDatumReader);
User tmp = null;
while (dataFileReader.hasNext()) {
// Reuse user object by passing it to next(). This saves us from
// allocating and garbage collecting many objects for files with
// many items.
tmp = dataFileReader.next(tmp);
System.out.println(tmp);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
也说动态代理3
Hadoop RPC中设计的基本设计模式就是代理模式,因此想要看懂RPC部分源码,代理不可不知。
代理模式是常用的java设计模式,他的特征是代理类与委托类有同样的接口,代理类主要负责为委托类预处理消息、过滤消息、把消息转发给委托类,以及事后处理消息等。代理类与委托类之间通常会存在关联关系,一个代理类的对象与一个委托类的对象关联,代理类的对象本身并不真正实现服务,而是通过调用委托类的对象的相关方法,来提供特定的服务。
按照代理的创建时期,代理类可以分为两种。
- 静态代理:由程序员创建或特定工具自动生成源代码,再对其编译。在程序运行前,代理类的.class文件就已经存在了。
- 动态代理:在程序运行时,运用反射机制动态创建而成。
静态代理的基本原理我们就不说了,简而言之就是代理类和委托类实现相同的借口,Client通过代理类调用实现类的方法(代理类持有委托类的实例)。然后这样做有一个很明显的弊端,那就是每一个代理类只能为一个接口服务,这样一来程序开发中必然会产生过多的代理,而且,所有的代理操作除了调用的方法不一样之外,其他的操作都一样,则此时肯定是重复代码。解决这一问题最好的做法是可以通过一个代理类完成全部的代理功能,那么此时就必须使用动态代理完成。动态代理类的字节码在程序运行时由Java反射机制动态生成,无需程序员手工编写它的源代码。动态代理类不仅简化了编程工作,而且提高了软件系统的可扩展性,因为Java反射机制可以生成任意类型的动态代理类。java.lang.reflect包中的Proxy类和InvocationHandler 接口提供了生成动态代理类的能力。
InvocationHandler接口:
public interface InvocationHandler {
public Object invoke(Object proxy,Method method,Object[] args) throws Throwable;
}
参数说明:
Object proxy:指被代理的对象。
Method method:要调用的方法
Object[] args:方法调用时所需要的参数
可以将InvocationHandler接口的子类想象成一个代理的最终操作类,替换掉ProxySubject。
Proxy类是专门完成代理的操作类,可以通过此类为一个或多个接口动态地生成实现类,此类提供了如下的操作方法:
public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces,
InvocationHandler h) throws IllegalArgumentException
参数说明:
ClassLoader loader:类加载器
Class<?>[] interfaces:得到全部的接口
InvocationHandler h:得到InvocationHandler接口的子类实例
NOTE:类加载器 在Proxy类中的newProxyInstance()方法中需要一个ClassLoader类的实例,ClassLoader实际上对应的是类加载器,在Java中主要有以下三种类加载器;
- Booststrap ClassLoader:此加载器采用C++编写,一般开发中是看不到的;
- Extension ClassLoader:用来进行扩展类的加载,一般对应的是jre\lib\ext目录中的类;
- AppClassLoader:(默认)加载classpath指定的类,是最常使用的是一种加载器。
以下给出一具体实例:
//BookFacade.java,define interfaces
package org.qingyuanxingsi.proxypattern;
public interface BookFacade {
//Add book interface
public void addBook();
}
//BookFacadeImpl.java,具体实现类
package org.qingyuanxingsi.proxypattern;
public class BookFacadeImpl implements BookFacade {
@Override
public void addBook() {
// TODO Auto-generated method stub
System.out.println("Adding books to the database!");
}
}
//BookFacadeProxy.java,生成动态代理
package org.qingyuanxingsi.proxypattern;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class BookFacadeProxy implements InvocationHandler {
private Object target;
public Object bind(Object target){
this.target = target;
//Get the proxy object
//Interfaces must be bound,this is one drawback(which can be fixed by cglib)
return Proxy.newProxyInstance(target.getClass().getClassLoader(), target.getClass().getInterfaces(), this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
// TODO Auto-generated method stub
Object result = null;
System.out.println("Transaction begins!");
//Execute the method
result = method.invoke(target, args);
System.out.println("Transaction ends!");
return result;
}
}
//TestProxy.java,test case
package org.qingyuanxingsi.proxypattern;
public class TestProxy {
public static void main(String[] args) {
// TODO Auto-generated method stub
BookFacadeProxy proxy = new BookFacadeProxy();
BookFacade bookProxy = (BookFacade)proxy.bind(new BookFacadeImpl());
bookProxy.addBook();
}
}
但是,JDK的动态代理依靠接口实现,如果有些类并没有实现接口,则不能使用JDK代理,这就要使用cglib动态代理了。JDK的动态代理机制只能代理实现了接口的类,而不能实现接口的类就不能实现JDK的动态代理,cglib是针对类来实现代理的,他的原理是对指定的目标类生成一个子类,并覆盖其中方法实现增强,但因为采用的是继承,所以不能对final修饰的类进行代理。具体示例如下:
//BookFacadeImpl1.java,没有实现接口的实现类
package net.battier.dao.impl;
/**
* 这个是没有实现接口的实现类
*
* @author student
*
*/
public class BookFacadeImpl1 {
public void addBook() {
System.out.println("增加图书的普通方法...");
}
}
//BookfacadeCglib.java,使用cglib实现动态代理
package net.battier.proxy;
import java.lang.reflect.Method;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
/**
* 使用cglib动态代理
*
* @author student
*
*/
public class BookFacadeCglib implements MethodInterceptor {
private Object target;
/**
* 创建代理对象
*
* @param target
* @return
*/
public Object getInstance(Object target) {
this.target = target;
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(this.target.getClass());
// 回调方法
enhancer.setCallback(this);
// 创建代理对象
return enhancer.create();
}
@Override
// 回调方法
public Object intercept(Object obj, Method method, Object[] args,
MethodProxy proxy) throws Throwable {
System.out.println("事物开始");
proxy.invokeSuper(obj, args);
System.out.println("事物结束");
return null;
}
}
//TestCglib.java,a test case
package net.battier.test;
import net.battier.dao.impl.BookFacadeImpl1;
import net.battier.proxy.BookFacadeCglib;
public class TestCglib {
public static void main(String[] args) {
BookFacadeCglib cglib=new BookFacadeCglib();
BookFacadeImpl1 bookCglib=(BookFacadeImpl1)cglib.getInstance(new BookFacadeImpl1());
bookCglib.addBook();
}
}
Dive Into Hadoop RPC
好吧,具备了以上两个基础知识后,我们可以一睹Hadoop RPC的真面目了。
RPC通信模型
RPC 是一种通过网络从远程计算机上请求服务,但不需要了解底层网络技术的协议。RPC协议假定某些传输协议(如TCP或UDP等)已经存在,并通过这些传输协议为通信程序之间传递访问请求或者应答信息。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发分布式应用程序更加容易。RPC通常采用客户机 / 服务器模型。请求程序是一个客户机,而服务提供程序则是一个服务器。一个典型的RPC框架如下图所示,主要包括以下几个部分:
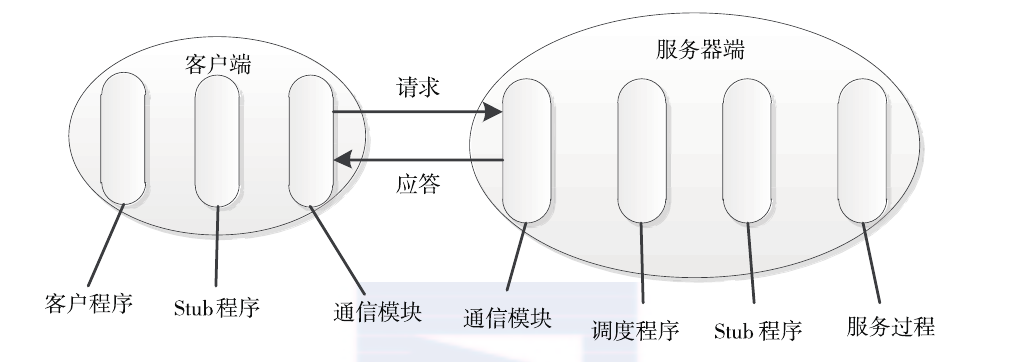
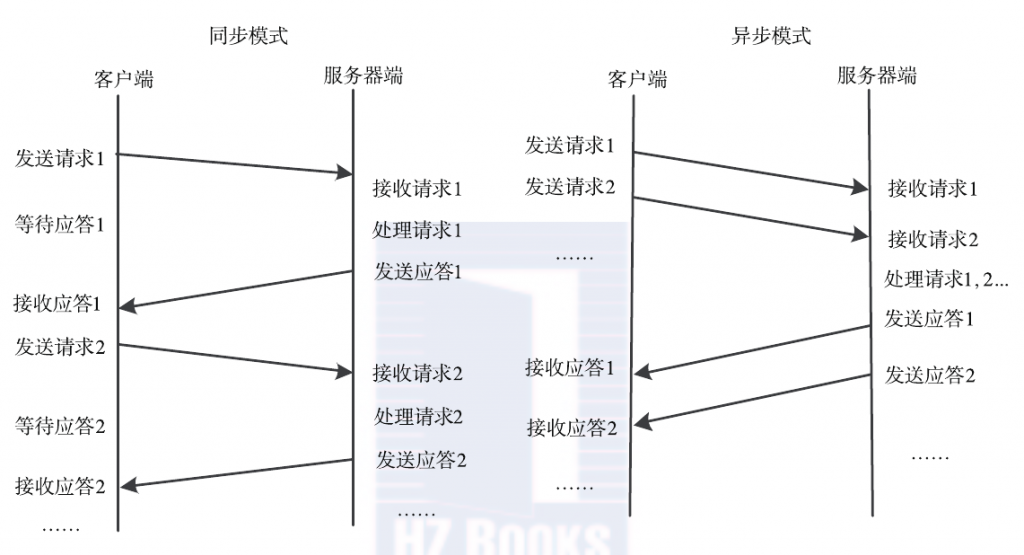
- 通信模块。两个相互协作的通信模块实现请求-应答协议,它们在客户和服务器之间传递请求和应答消息,一般不会对数据包进行任何处理。请求–应答协议的实现方式有同步方式和异步方式两种。如下图所示,同步模式下客户端程序一直阻塞到服务器端发送的应答请求到达本地; 而异步模式不同,客户端将请求发送到服务器端后,不必等待应答返回,可以做其他事情,待服务器端处理完请求后,主动通知客户端。在高并发应用场景中,一般采用异步模式以降低访问延迟和提高带宽利用率。
- Stub 程序。客户端和服务器端均包含Stub程序,可将之看做代理程序。它使得远程函数调用表现得跟本地调用一样,对用户程序完全透明。在客户端,它表现得就像一个本地程序,但不直接执行本地调用,而是将请求信息通过网络模块发送给服务器端。此外,当服务器发送应答后,它会解码对应结果。在服务器端,Stub程序依次进行解码请求消息中的参数、调用相应的服务过程和编码应答结果的返回值等处理。
- 调度程序。调度程序接收来自通信模块的请求消息,并根据其中的标识选择一个Stub程序进行处理。通常客户端并发请求量比较大时,会采用线程池提高处理效率。
- 客户程序/服务过程。请求的发出者和请求的处理者。如果是单机环境,客户程序可直接通过函数调用访问服务过程,但在分布式环境下,需要考虑网络通信,这不得增加通信模块和Stub程序(保证函数调用的透明性)。
通常而言,一个 RPC 请求从发送到获取处理结果,所经历的步骤如下所示。
- 客户程序以本地方式调用系统产生的Stub程序;
- 该Stub程序将函数调用信息按照网络通信模块的要求封装成消息包,并交给通信模块发送到远程服务器端。
- 远程服务器端接收此消息后,将此消息发送给相应的Stub程序;
- Stub程序拆封消息,形成被调过程要求的形式,并调用对应函数;
- 被调用函数按照所获参数执行,并将结果返回给Stub程序;
- Stub程序将此结果封装成消息,通过网络通信模块逐级地传送给客户程序。
RPC总体架构
同其他RPC框架一样,Hadoop RPC主要分为四个部分,分别是序列化层、函数调用层、网络传输层和服务器端处理框架,具体实现机制如下:
- 序列化层。序列化主要作用是将结构化对象转为字节流以便于通过网络进行传输或写入持久存储,在RPC框架中,它主要用于将用户请求中的参数或者应答转化成字节流以便跨机器传输。前面介绍的Protocol Buffers和Apache Avro均可用在序列化层,Hadoop本身也提供了一套序列化框架,一个类只要实现Writable接口即可支持对象序列化与反序列化。
- 函数调用层。函数调用层主要功能是定位要调用的函数并执行该函数,Hadoop RPC采用了Java反射机制与动态代理实现了函数调用。
- 网络传输层。网络传输层描述了Client与Server之间消息传输的方式,Hadoop RPC采用了基于TCP/IP的Socket机制。
- 服务器端处理框架。服务器端处理框架可被抽象为网络I/O模型,它描述了客户端与服务器端间信息交互方式,它的设计直接决定着服务器端的并发处理能力,常见的网络 I/O 模型有阻塞式 I/O、非阻塞式 I/O、事件驱动 I/O 等,而Hadoop RPC采用了基于Reactor设计模式的事件驱动 I/O 模型。
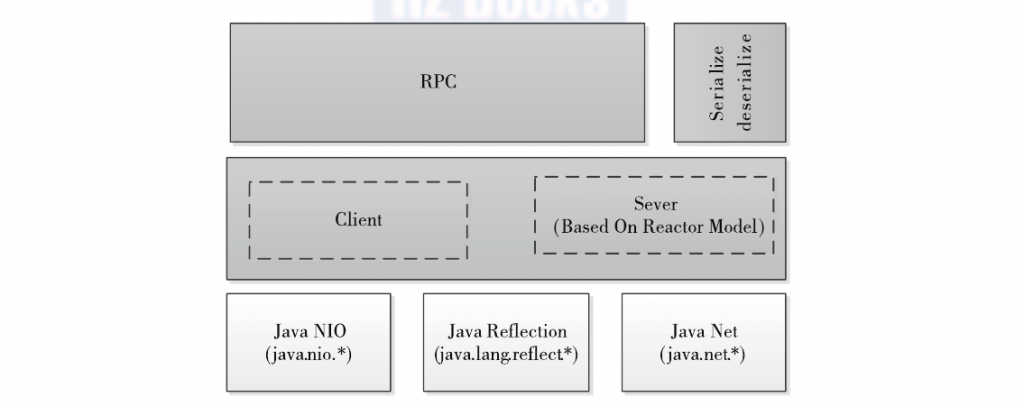
Hadoop RPC 总体架构如下图所示,自下而上可分为两层,第一层是一个基于Java NIO (New I/O)实现的客户机–服务器(C/S)通信模型。其中,客户端将用户的调用方法及其参数封装成请求包后发送到服务器端。服务器端收到请求包后,经解包、调用函数、打包结果等一系列操作后,将结果返回给客户端。为了增强Sever端的扩展性和并发处理能力,Hadoop RPC采用了基于事件驱动的Reactor设计模式,在具体实现时,用到了JDK提供的各种功能包,主要包括java.nio(NIO)、java.lang.reflect(反射机制和动态代理)、java.net(网络编程库)等。第二层是供更上层程序直接调用的 RPC 接口,这些接口底层即为C/S通信模型。
Hadoop RPC使用方法
Hadoop RPC 对外主要提供了两种接口(见类 org.apache.hadoop.ipc.RPC),分别是:
//Construct a client proxy instance for sending RPC requests to server
public static <T> ProtocolProxy <T> getProxy/waitForProxy(...)
//Build a server instance for a specific protocol,handle requests
public static Server RPC.Builder (Configuration).build()
通常而言,使用Hadoop RPC可分为以下4个步骤。
-
定义 RPC 协议 RPC协议是客户端和服务器端之间的通信接口,它定义了服务器端对外提供的服务接口。如下所示,我们定义一个ClientProtocol通信接口,声明了echo()和add()两个方法。需要注意的是,Hadoop 中所有自定义 RPC 接口都需要继承VersionedProtocol接口,它描述了协议的版本信息。
interface ClientProtocol extends org.apache.hadoop.ipc.VersionedProtocol { // 版本号,默认情况下,不同版本号的 RPC Client 和 Server 之间不能相互通信 public static final long versionID = 1L; String echo(String value) throws IOException; int add(int v1, int v2) throws IOException; } -
实现 RPC 协议 Hadoop RPC协议通常是一个Java 接口,用户需要实现该接口。对ClientProtocol接口进行简单的实现如下所示:
public static class ClientProtocolImpl implements ClientProtocol { // 重载的方法,用于获取自定义的协议版本号, public long getProtocolVersion(String protocol, long clientVersion) { return ClientProtocol.versionID; } // 重载的方法,用于获取协议签名 public ProtocolSignature getProtocolSignature(String protocol, long clientVersion, inthashcode) { return new ProtocolSignature(ClientProtocol.versionID, null); } public String echo(String value) throws IOException { return value; } public int add(int v1, int v2) throws IOException { return v1 + v2; } } -
构造并启动 RPC Server 直接使用静态类Builder构造一个RPC Server,并调用函数start()启动该Server:
Server server = new RPC.Builder(conf).setProtocol(ClientProtocol.class) .setInstance(new ClientProtocolImpl()).setBindAddress(ADDRESS).setPort(0) .setNumHandlers(5).build(); server.start();其中,BindAddress(由函数setBindAddress设置)和Port(由函数setPort设置,0表示由系统随机选择一个端口号)分别表示服务器的host和监听端口号,而 NnumHandlers(由函数setNumHandlers设置)表示服务器端处理请求的线程数目。到此为止,服务器处理监听状态,等待客户端请求到达。 4. 构造 RPC Client 并发送 RPC 请求 使用静态方法getProxy构造客户端代理对象,直接通过代理对象调用远程端的方法,具体如下所示:
proxy = (ClientProtocol)RPC.getProxy(ClientProtocol.class, ClientProtocol.versionID, addr, conf); int result = proxy.add(5, 6); String echoResult = proxy.echo("result");
经过以上四步,我们便利用Hadoop RPC搭建了一个非常高效的客户机–服务器网络模型。接下来,我们将深入到Hadoop RPC内部,剖析它的设计原理及技巧。
Hadoop RPC类详解
Hadoop RPC主要由三个大类组成,即RPC、Client和Server,分别对应对外编程接口、客户端实现和服务器实现。
- ipc.RPC类分析 RPC类实际上是对底层客户机–服务器网络模型的封装,以便为程序员提供一套更方便简洁的编程接口。

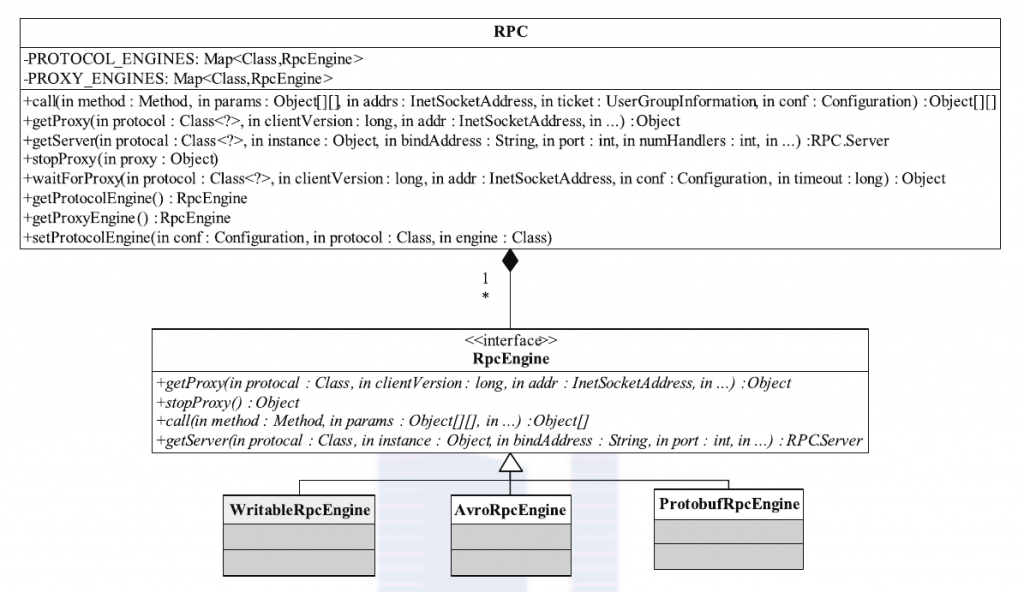
如上图所示,RPC 类定义了一系列构建和销毁RPC客户端的方法,构建方法分为getProxy和waitForProxy两类,销毁方只有一个,即为stopProxy。RPC服务器的构建则由静态内部类RPC.Builder,该类提供了一些列setXxx 方法(Xxx 为某个参数名称)供用户设置一些基本的参数,比如RPC 协议、RPC协议实现对象、服务器绑定地址、端口号等,一旦设置完成这些参数后,可通过调用RPC.Builder.build()完成一个服务器对象的构建,之后直接调用 Server.start() 方法便可以启动该服务器。与Hadoop 1.x中的RPC仅支持基于Writable序列化方式不同,Hadoop2.x允许用户使用其他序列化框架,比如Protocol Buffers等,目前提供了 Writable(WritableRpcEngine)和Protocol Buffers(ProtobufRpcEngine)两种,默认实现是Writable方式,用户可通过调用RPC.setProtocolEngine(...)修改采用的序列化方式。
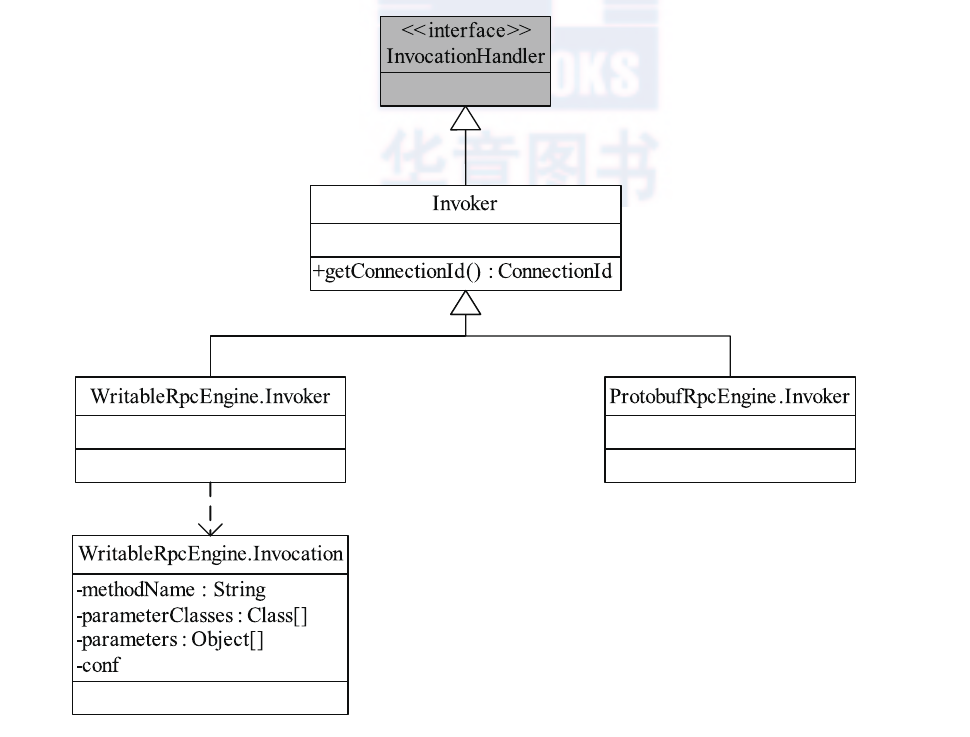
下面以采用 Writable序列化为例(采用Protocol Buffers的过程类似),介绍Hadoop RPC的远程过程调用流程。Hadoop RPC使用了Java动态代理完成对远程方法的调用:用户只需实现java.lang.reflect.InvocationHandler接口,并按照自己需求实现invoke方法即可完成动态代理类对象上的方法调用。但对于HadoopRPC,函数调用由客户端发出,并在服务器端执行并返回,因此不能像单机程序那样直接在invoke方法中本地调用相关函数,它的做法是,在invoke方法中,将函数调用信息(函数名,函数参数列表等)打包成可序列化的WritableRpcEngine.Invocation 对象,并通过网络发送给服务器端,服务端收到该调用信息后,解析出和函数名,函数参数列表等信息,利用Java反射机制完成函数调用,期间涉及到的类关系如下图所示。
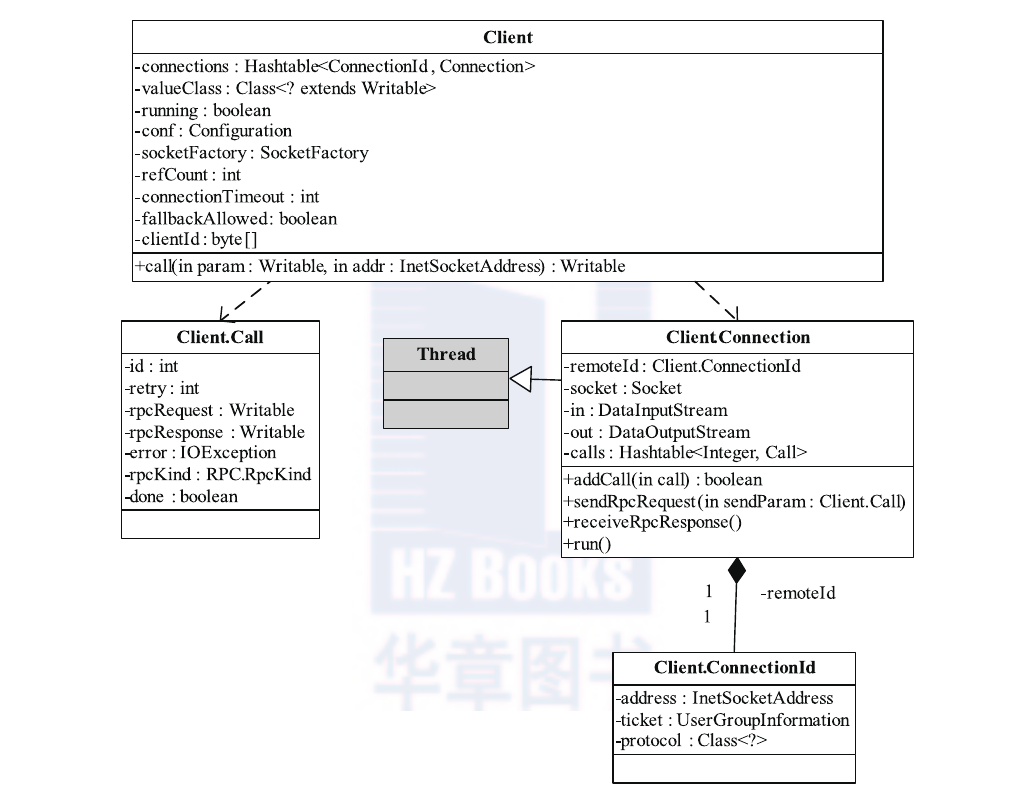
- ipc.Client Client主要完成的功能是发送远程过程调用信息并接收执行结果。它涉及到的类关系如下图所示:
Client类对外提供了一类执行远程调用的接口,这些接口的名称一样,仅仅是参数列表不同,比如其中一个的声明如下所示:
public Writable call(Writable param, ConnectionIdremoteId)
throws InterruptedException, IOException;
Client 内部有两个重要的内部类,分别是Call和Connection。
- Call 类 :封装了一个RPC请求,它包含5个成员变量,分别是唯一标识id、函数调用信息param、函数执行返回值value、出错或者异常信息error和执行完成标识符done。由于Hadoop RPC Server采用异步方式处理客户端请求,这使远程过程调用的发生顺序与结果返回顺序无直接关系,而Client端正是通过id识别不同的函数调用的。当客户端向服务器端发送请求时,只需填充id和param两个变量,而剩下的3个变量(value、error和done)则由服务器端根据函数执行情况填充。
- Connection 类:Client与每个Server之间维护一个通信连接,与该连接相关的基本信息及操作被封装到Connection类中,基本信息主要包括通信连接唯一标识(remoteId)、与Server端通信的Socket(socket)、网络输入数据流(in)、网络输出数据流(out)、保存RPC请求的哈希表(calls)等。操作则包括: ❍ addCall—将一个Call对象添加到哈希表中; ❍ sendParam—向服务器端发送RPC请求; ❍ receiveResponse—从服务器端接收已经处理完成的RPC请求; ❍ run—Connection 是一个线程类,它的run方法调用了receiveResponse方法,会一直等待接收 RPC 返回结果。
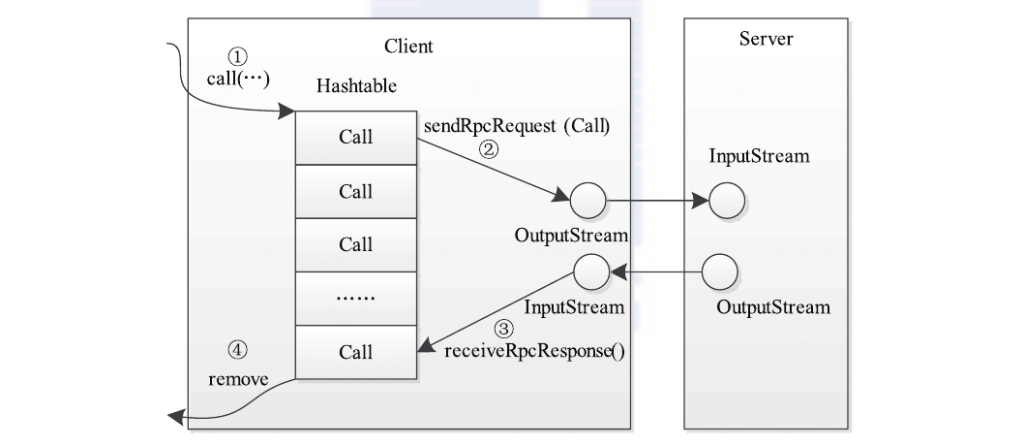
当调用call函数执行某个远程方法时,Client端需要进行(如下图所示)以下4个步骤。
- 创建一个Connection 对象,并将远程方法调用信息封装成Call对象,放到Connection对象中的哈希表中;
- 调用 Connection 类中的sendRpcRequest()方法将当前Call对象发送给Server端;
- Server端处理完RPC请求后,将结果通过网络返回给Client端,Client端通过receiveRpcResponse()函数获取结果;
- Client检查结果处理状态(成功还是失败),并将对应 Call 对象从哈希表中删除。
- ipc.Server 类分析
Hadoop采用了Master/Slave 结构,其中Master是整个系统的单点,如NameNode或JobTracker ,这是制约系统性能和可扩展性的最关键因素之一 ;而Master通过ipc.Server接收并处理所有Slave发送的请求,这就要求ipc.Server将高并发和可扩展性作为设计目标为此,ipc.Server采用了很多提高并发处理能力的技术,主要包括线程池、事件驱动和Reactor设计模式等,这些技术均采用了JDK自带的库实现,这里重点分析它是如何利用Reactor设计模式提高整体性能的。HDFS的单点故障已经在Hadoop 2.0中得到了解决,MRv1中的JobTracker的单点故障在CDH4中也得到了解决。
Reactor4是并发编程中的一种基于事件驱动的设计模式,它具有以下两个特点:通过派发/分离I/O操作事件提高系统的并发性能;提供了粗粒度的并发控制,使用单线程实现,避免了复杂的同步处理。典型的Reactor实现原理如下图所示。
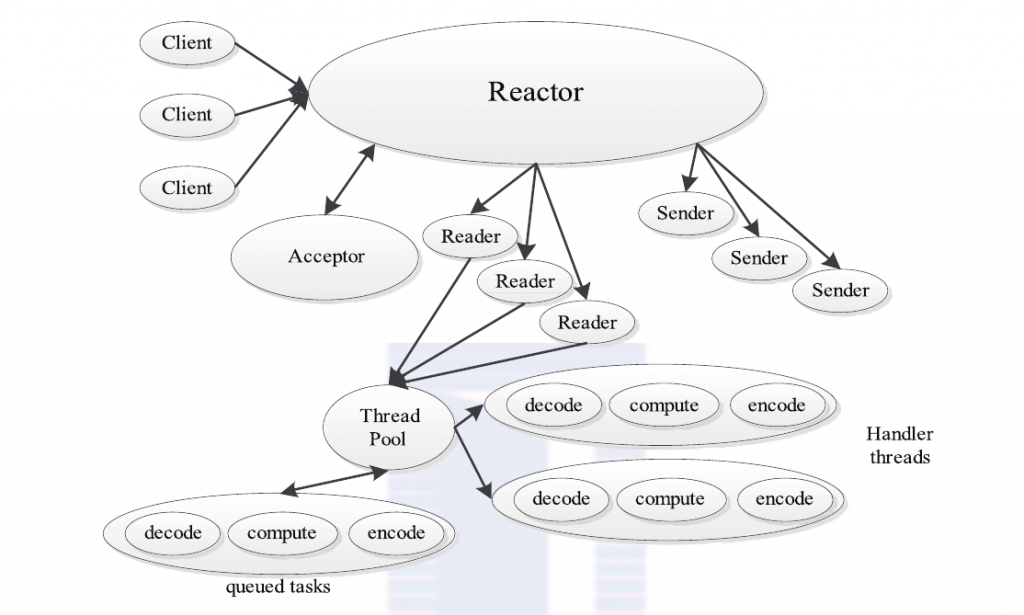
典型的Reactor模式中主要包括以下几个角色。
❑ Reactor:I/O事件的派发者。
❑ Acceptor:接受来自Client的连接,建立与Client对应的Handler,并向Reactor注册此Handler。
❑ Handler :与一个Client通信的实体,并按一定的过程实现业务的处理。Handler内部往往会有更进一步的层次划分,用来抽象诸如read、decode、compute、encode和send等过程。在Reactor模式中,业务逻辑被分散的I/O事件所打破,所以Handler需要有适当的机制在所需的信息还不全(读到一半)的时候保存上下文,并在下一次I/O事件到来的时候(另一半可读)能继续上次中断的处理。
❑Reader/Sender:为了加速处理速度,Reactor模式往往构建一个存放数据处理线程的线程池,这样数据读出后,立即扔到线程池中等待后续处理即可。为此,Reactor模式一般分离Handler中的读和写两个过程,分别注册成单独的读事件和写事件,并由对应的Reader和Sender线程处理。
ipc.Server实际上实现了一个典型的Reactor设计模式,其整体架构与上述完全一致。一旦读者了解典型 Reactor 架构便可很容易地学习 ipc.Server的设计思路及实现。接下来,我们分析ipc.Server的实现细节。
前面提到,ipc.Server的主要功能是接收来自客户端的RPC 请求,经过调用相应的函数获取结果后,返回给对应的客户端。为此,ipc.Server 被划分成3个阶段:接收请求、处理请求和返回结果,如下图所示。各阶段实现细节如下。
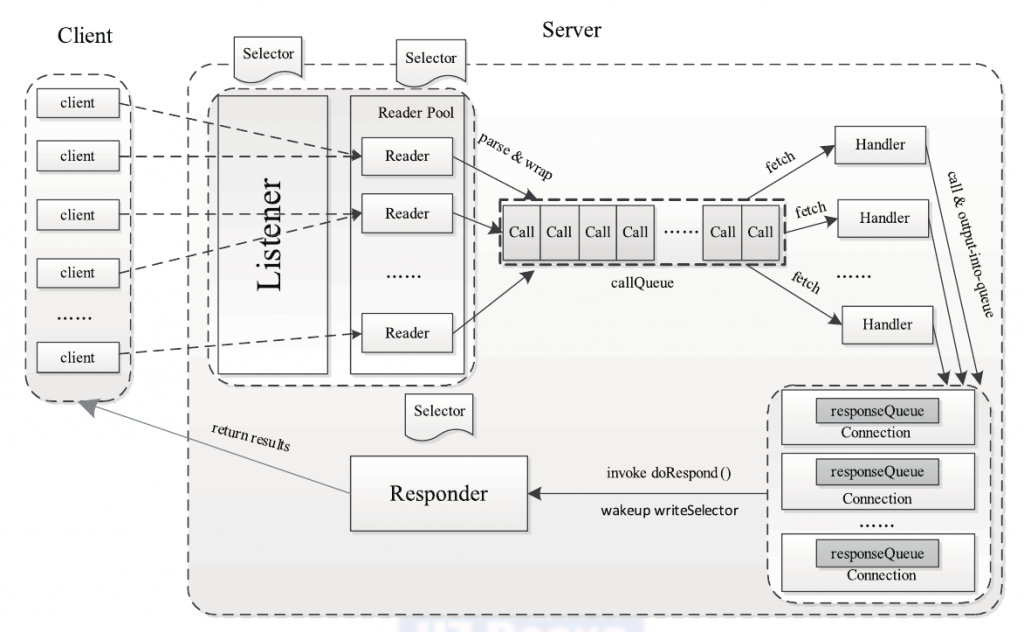
- 接收请求;该阶段主要任务是接收来自各个客户端的RPC请求,并将它们封装成固定的格式(Call类)放到一个共享队列(callQueue)中,以便进行后续处理。该阶段内部又分为建立连接和接收请求两个子阶段,分别由Listener和Reader两种线程完成。整个Server只有一个Listener线程,统一负责监听来自客户端的连接请求,一旦有新的请求到达,它会采用轮询的方式从线程池中选择一个Reader线程进行处理,而Reader线程可同时存在多个,它们分别负责接收一部分客户端连接的RPC请求,至于每个Reader线程负责哪些客户端连接,完全由Listener决定,当前Listener只是采用了简单的轮询分配机制。Listener和Reader线程内部各自包含一个Selector对象,分别用于监听SelectionKey.OP_ACCEPT和SelectionKey.OP_READ 事件。对于Listener线程,主循环的实现体是监听是否有新的连接请求到达,并采用轮询策略选择一个Reader线程处理新连接;对于Reader线程,主循环的实现体是监听(它负责的那部分)客户端连接中是否有新的RPC请求到达,并将新的RPC请求封装成Call对象,放到共享队列callQueue 中。
- 处理请求;该阶段主要任务是从共享队列callQueue中获取Call对象,执行对应的函数调用,并将结果返回给客户端,这全部由Handler线程完成。Server 端可同时存在多个Handler线程,它们并行从共享队列中读取Call对象,经执行对应的函数调用后,将尝试着直接将结果返回给对应的客户端。但考虑到某些函数调用返回结果很大或者网络速度过慢,可能难以将结果一次性发送到客户端,此时Handler将尝试着将后续发送任务交给Responder线程。
- 返回结果;前面提到,每个Handler线程执行完函数调用后,会尝试着将执行结果返回给客户端,但对于特殊情况,比如函数调用返回结果过大或者网络异常情况(网速过慢),会将发送任务交给Responder线程。Server端仅存在一个Responder线程,它的内部包含一个Selector对象,用于监听SelectionKey.OP_WRITE事件。当Handler没能将结果一次性发送到客户端时,会向该Selector对象注册SelectionKey.OP_WRITE事件,进而由Responder 线程采用异步方式继续发送未发送完成的结果。
Hadoop RPC流程剖析
以下我们对Hadoop Yarn的具体实现进行剖析。Hadoop YARN将RPC中的序列化部分剥离开,以便将现有的开源RPC框架集成进来。经过改进之后,Hadoop RPC的类关系如下图所示,RPC类变成了一个工厂,它将具体的RPC实现授权给RpcEngine实现类,而现有的开源RPC只要实现RpcEngine接口,便可以集成到Hadoop RPC中。在该图中,WritableRpcEngine是采用Hadoop自带的序列化框架实现的RPC,而AvroRpcEngine和ProtobufRpcEngine分别是开源RPC(或序列化)框架Apache Avro和Protocol Buffers对应的 RpcEngine 实现,用户可通过配置参数rpc.engine.{protocol}以指定协议 {protocol} 采用的序列化方式。需要注意的是,当前实现中,Hadoop RPC 只是采用了这些开源框架的序列化机制,底层的函数调用机制仍采用 Hadoop 自带的。YARN提供的对外类是YarnRPC,用户只需使用该类便可以构建一个基于Hadoop RPC且采用Protocol Buffers序列化框架的通信协议。YarnRPC相关实现类如下图所示。
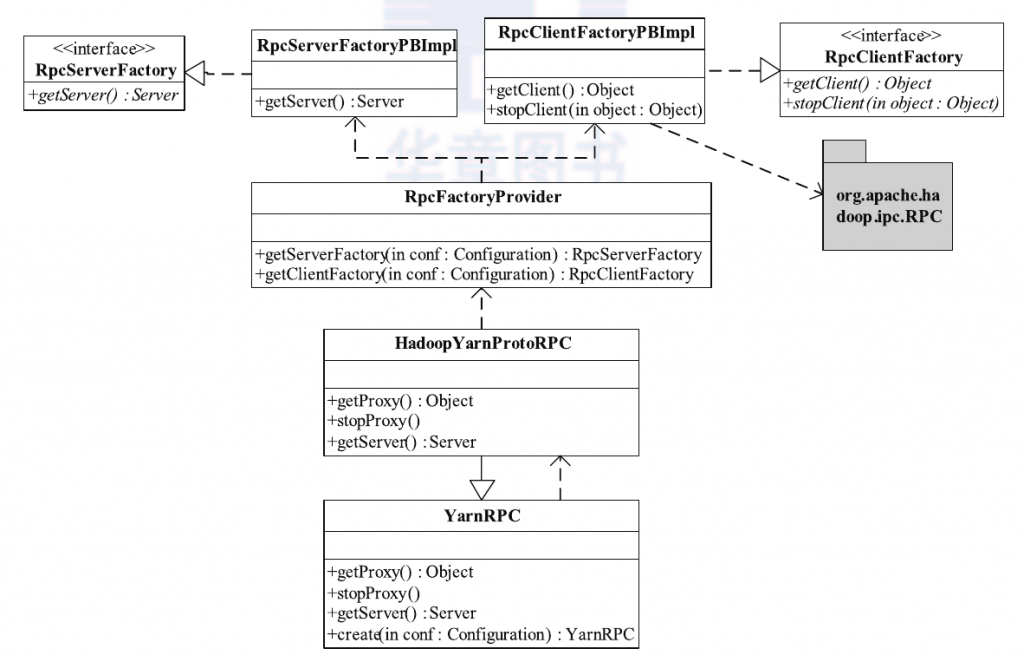
YarnRPC是一个抽象类,实际的实现由参数yarn.ipc.rpc.class指定,默认值是org.apache.hadoop.yarn.ipc.HadoopYarnProtoRPC。HadoopYarnProtoRPC 通过RPC工厂生成器(工厂设计模式)RpcFactoryProvider生成客户端工厂(由参数yarn.ipc.client.factory.class指定,默认值是 org.apache.hadoop.yarn.factories.impl.pb.RpcClientFactoryPBImpl)和服务器工厂(由参数yarn.ipc.server.factory.class指定,默认值 是org.apache.hadoop.yarn.factories.impl.pb.RpcServerFactoryPBImpl),以根据通信协议的Protocol Buffers定义生成客户端对象和服 务器对象。
- RpcClientFactoryPBImpl : 根据通信协议接口(实际上就是一个Java interface)及Protocol Buffers定义构造RPC客户端句柄, 但它对通 信协议的存放位置和类名命有一定要求。假设通信协议接口Xxx所在Java包名为XxxPackage,则客户端实现代码必须位于Java包XxxPackage.impl.pb.client 中(在接口包名后面增加
.impl.pb.client), 且实现类名为PBClientImplXxx(在接口名前面增加前缀PBClientImpl)。 - RpcServerFactoryPBImpl :根据通信协议接口(实际上就是一个Java interface)及Protocol Buffers定义构造RPC服务器句柄(具体会调用前面节介绍的RPC.Server类),但它对通信协议的存放位置和类命名有一定要求。假设通信协议接口Xxx 所在Java 包名为 XxxPackage,则客户端实现代码必须位于Java包XxxPackage.impl.pb.server中(在接口包名后面增加
.impl.pb.server),且实现类名为PBServiceImplXxx(在接口名前面增加前缀PBServiceImpl)。
Hadoop YARN 已将Protocol Buffers作为默认的序列化机制(而不是Hadoop自带的Writable),这带来的好处主要表现在以下几个方面:
- 继承了 Protocol Buffers 的优势.Protocol Buffers已在实践中证明了其高效性、可扩展性、紧凑性和跨语言特性。首先,它允许在保持向后兼容性的前提下修改协议,比如为某个定义好的数据格式添加一个新的字段 ;其次,它支持多种语言,进而方便用户为某些服务(比如 HDFS 的 NameNode)编写非 Java 客户端 ;此外,实验 表明 Protocol Buffers 比 Hadoop 自带的 Writable 在性能方面有很大提升。
- 支持升级回滚。Hadoop 2.0已经将 NameNode HA方案合并进来,在该方案中,Name-Node 分为Active和Standby两种角色,其中, Active NameNode 在当前对外提供服务,而Standby NameNode则是能够在Active NameNode出现故障时接替它。采用Protocol Buffers序列化机制后,管理员能够在不停止NameNode对外服务的前提下,通过主备NameNode之间的切换,依次对主备NameNode进行在线升级(不用考虑版本和协议兼容性等问题)。
为了进一步说明 YARN RPC 的使用方法,本小节给出一个具体的应用实例。 在 YARN 中,ResourceManager和NodeManager之间的通信协议是ResourceTracker,其中NodeManager是该协议的客户端,ResourceManager是服务端,NodeManager通过该协议中定义的两个RPC函数(registerNodeManager和nodeHeartbeat)向ResourceManager注册和周期性发送心跳信息。ResourceManager(服务器端)中的相关代码如下:
// ResourceTrackerService 实现了 ResourceTracker 通信接口,并启动 RPC Server
public class ResourceTrackerService extends AbstractService implements
ResourceTracker {
private Server server;
...
protected void serviceStart() throws Exception {
super.serviceStart();
Configuration conf = getConfig();
YarnRPC rpc = YarnRPC.create(conf); // 使用 YarnRPC 类
this.server = rpc.getServer(ResourceTracker.class, this, resourceTrackerAddress,
conf, null, conf.getInt(YarnConfiguration.RM_RESOURCE_TRACKER_CLIENT_THREAD_COUNT,
YarnConfiguration.DEFAULT_RM_RESOURCE_TRACKER_CLIENT_THREAD_COUNT));
this.server.start();
}
...
@Override
public RegisterNodeManagerResponse registerNodeManager(
RegisterNodeManagerRequest request) throws YarnException,
IOException {
// 具体实现
}
@Override
public NodeHeartbeatResponse nodeHeartbeat(NodeHeartbeatRequest request)
throws YarnException, IOException {
// 具体实现
}
}
NodeManager(客户端)中的相关代码如下。
//该函数是从YARN源代码中简单修改而来的
protected ResourceTracker getRMClient() throws IOException {
Configuration conf = getConfig();
InetSocketAddress rmAddress = getRMAddress(conf, protocol);
RetryPolicy retryPolicy = createRetryPolicy(conf);
ResourceTracker proxy = RMProxy.<T>getProxy(conf, ResourceTracker.class, rmAddress);
LOG.info("Connecting to ResourceManager at " + rmAddress);
return (ResourceTracker) RetryProxy.create(protocol, proxy, retryPolicy);
}
...
this.resourceTracker = getRMClient();
...
RegisterNodeManagerResponse regNMResponse = resourceTracker.registerNodeManager(request);
...
response = resourceTracker.nodeHeartbeat(request);
为了能够让以上代码正常工作,YARN 按照以下流程实现各种功能。
步骤1 定义通信协议接口(Java Interface)。定义通信协议接口ResourceTracker,它包含registerNodeManager和nodeHeartbeat两个函数,且每个函数包含一个参数和一个返 回值,具体如下:
public interface ResourceTracker {
public RegisterNodeManagerResponse registerNodeManager(
RegisterNodeManagerRequest request) throws YarnException, IOException;
public NodeHeartbeatResponse nodeHeartbeat(NodeHeartbeatRequest request)
throws YarnException, IOException;
}
步骤2 为通信协议ResourceTracker提供Protocol Buffers定义和Java实现。前面提到,Protocol Buffers仅提供了序列化框架,但未提供RPC实现,因此RPC部分需要由用户自己实现,而YARN 则让ResourceTrackerService 类实现了ResourceTracker协议,它的 Protocol Buffers 定义(具体见文件ResourceTracker.proto)如下:
option java_package = "org.apache.hadoop.yarn.proto";
option java_outer_classname = "ResourceTracker";
option java_generic_services = true;
option java_generate_equals_and_hash = true;
import "yarn_server_common_service_protos.proto";
service ResourceTrackerService {
rpc registerNodeManager(RegisterNodeManagerRequestProto) returns (RegisterNode
ManagerResponseProto);
rpc nodeHeartbeat(NodeHeartbeatRequestProto) returns (NodeHeartbeatResponseProto);
}
ResourceTracker的RPC函数实现是由ResourceManager中的ResourceTrackerService完成的。
步骤3 为RPC函数的参数和返回值提供Protocol Buffers定义。YARN需要保证每个RPC函数的参数和返回值是采用Protocol Buffers定义的,因此 ResourceTracker协议中RegisterNodeManagerRequest、RegisterNodeManagerResponse、NodeHeartbeatRequest 和 NodeHeartbeatResponse 四个参数或者返回值需要使用Protocol Buffers定义,具体如下(见yarn_server_common_service_protos.proto 文件):
import "yarn_protos.proto";
import "yarn_server_common_protos.proto";
message RegisterNodeManagerRequestProto {
optional NodeIdProto node_id = 1;
optional int32 http_port = 3;
optional ResourceProto resource = 4;
}
message RegisterNodeManagerResponseProto {
optional MasterKeyProto container_token_master_key = 1;
optional MasterKeyProto nm_token_master_key = 2;
optional NodeActionProto nodeAction = 3;
optional int64 rm_identifier = 4;
optional string diagnostics_message = 5;
}
... // 其他几个参数和返回值的定义
步骤4 为RPC函数的参数和返回值提供Java定义和封装。YARN采用了Protocol Buffers 作为参数和返回值的序列化框架,且以原生态 .proto文件的方式给出了定义,而具体的Java代码生成需在代码编写之后完成。基于以上考虑,为了更容易使用Protocol Buffers生成的(Java 语言)参数和返回值定义,YARN RPC为每个RPC函数的参数和返回值提供Java定义和封装,以参数RegisterNodeManagerRequest 为例进行说明。 Java接口定义如下(见Java包org.apache.hadoop.yarn.server.api.protocolrecords):
public interface RegisterNodeManagerRequest {
NodeId getNodeId();
int getHttpPort();
Resource getResource();
void setNodeId(NodeId nodeId);
void setHttpPort(int port);
void setResource(Resource resource);
}
Java封装如下(见Java包org.apache.hadoop.yarn.server.api.protocolrecords.impl.pb):
public class RegisterNodeManagerRequestPBImpl extends
ProtoBase<RegisterNodeManagerRequestProto> implements RegisterNodeManagerRequest {
RegisterNodeManagerRequestProto proto = RegisterNodeManagerRequestProto.
getDefaultInstance();
RegisterNodeManagerRequestProto.Builder builder = null;
private NodeId nodeId = null;
...
@Override
public NodeId getNodeId() {
RegisterNodeManagerRequestProtoOrBuilder p = viaProto ? proto : builder;
if (this.nodeId != null) {
return this.nodeId;
}
if (!p.hasNodeId()) {
return null;
}
this.nodeId = convertFromProtoFormat(p.getNodeId());
return this.nodeId;
}
@Override
public void setNodeId(NodeId nodeId) {
maybeInitBuilder();
if (nodeId == null)
builder.clearNodeId();
this.nodeId = nodeId;
}
...
}
步骤5 为通信协议提供客户端和服务器端实现。客户端代码放在org.apache.hadoop.yarn.server.api.impl.pb.client 包中,且类名为 ResourceTrackerPBClientImpl,实现如下:
public class ResourceTrackerPBClientImpl implements ResourceTracker, Closeable {
private ResourceTrackerPB proxy;
public ResourceTrackerPBClientImpl(long clientVersion, InetSocketAddress addr,
Configuration conf) throws IOException {
RPC.setProtocolEngine(conf, ResourceTrackerPB.class, ProtobufRpcEngine.class);
proxy = (ResourceTrackerPB)RPC.getProxy(
ResourceTrackerPB.class, clientVersion, addr, conf);
}
@Override
public RegisterNodeManagerResponse registerNodeManager(
RegisterNodeManagerRequest request) throws YarnException,
IOException {
RegisterNodeManagerRequestProto requestProto = ((RegisterNodeManagerRequestP
BImpl)request).getProto();
try {
return new RegisterNodeManagerResponsePBImpl(proxy.registerNodeManager(null, requestProto));
} catch (ServiceException e) {
RPCUtil.unwrapAndThrowException(e);
return null;
}
}
...
}
服务端代码放在org.apache.hadoop.yarn.server.api.impl.pb.server包中,且类名为ResourceTrackerPBServerImpl,实现如下:
public class ResourceTrackerPBServiceImpl implements ResourceTrackerPB {
private ResourceTracker real;
public ResourceTrackerPBServiceImpl(ResourceTracker impl) {
this.real = impl;
}
@Override
public RegisterNodeManagerResponseProto registerNodeManager(
RpcController controller, RegisterNodeManagerRequestProto proto)
throws ServiceException {
RegisterNodeManagerRequestPBImpl request = new RegisterNodeManagerRequestPBImpl(proto);
try {
RegisterNodeManagerResponse response = real.registerNodeManager(request);
return ((RegisterNodeManagerResponsePBImpl)response).getProto();
} catch (YarnException e) {
throw new ServiceException(e);
} catch (IOException e) {
throw new ServiceException(e);
}
}
...
}
服务库与事件库
服务库
对于生命周期较长的对象,YARN采用了基于服务的对象管理模型对其进行管理,该模型主要有以下几个特点:
- 将每个被服务化的对象分为 4 个状态: NOTINITED(被创建)、 INITED(已初始化)、STARTED(已启动)、STOPPED(已停止)。
- 任何服务状态变化都可以触发另外一些动作。
- 可通过组合的方式对任意服务进行组合,以便进行统一管理。
YARN中关于服务模型的类图(位于包org.apache.hadoop.service中)如下图所示。
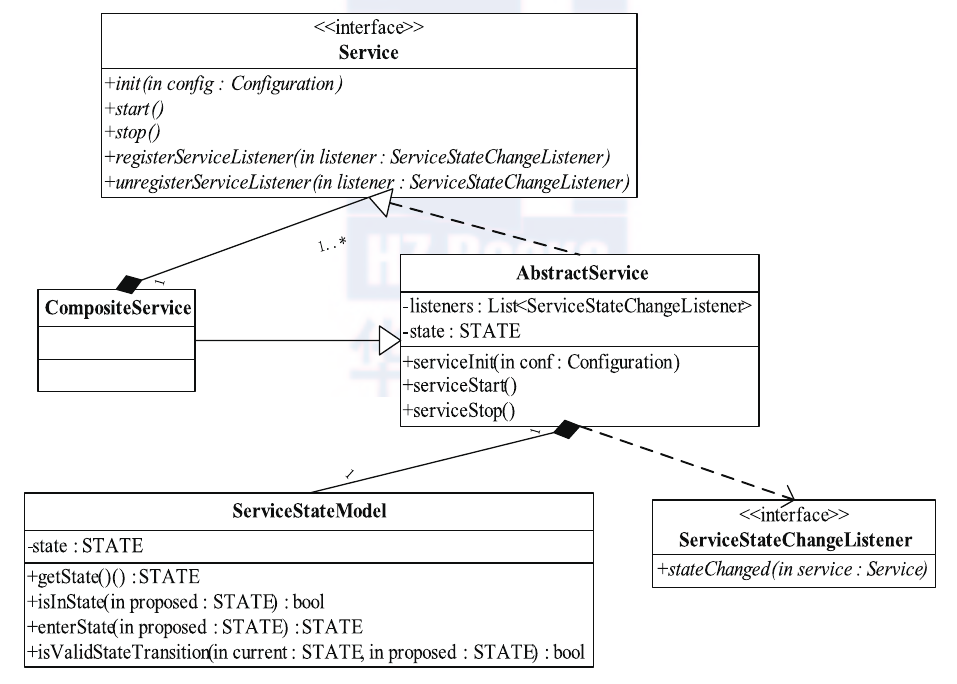
在这个图中,我们可以看到,所有的服务对象最终均实现了接口Service,它定义了最基本的服务初始化、启动、停止等操作,而AbstractService类提供了一个最基本的Service实现。YARN中所有对象,如果是非组合服务,直接继承AbstractService类即可,否则需继承CompositeService。比如,对于ResourceManager而言,它是一个组合服务,它组合了各种服务对象,包括ClientRMService、ApplicationMasterLauncher、ApplicationMasterService 等。在 YARN 中,ResourceManager和NodeManager属于组合服务,它们内部包含多个单一服务和组合服务,以实现对内部多种服务的统一管理。
事件库5
YARN采用了基于事件驱动的并发模型,该模型能够大大增强并发性,从而提高系统整体性能。为了构建该模型,YARN将各种处理逻辑抽象成事件和对应事件调度器,并将每类事件的处理过程分割成多个步骤,用有限状态机表示。YARN中的事件处理模型可概括为下图。
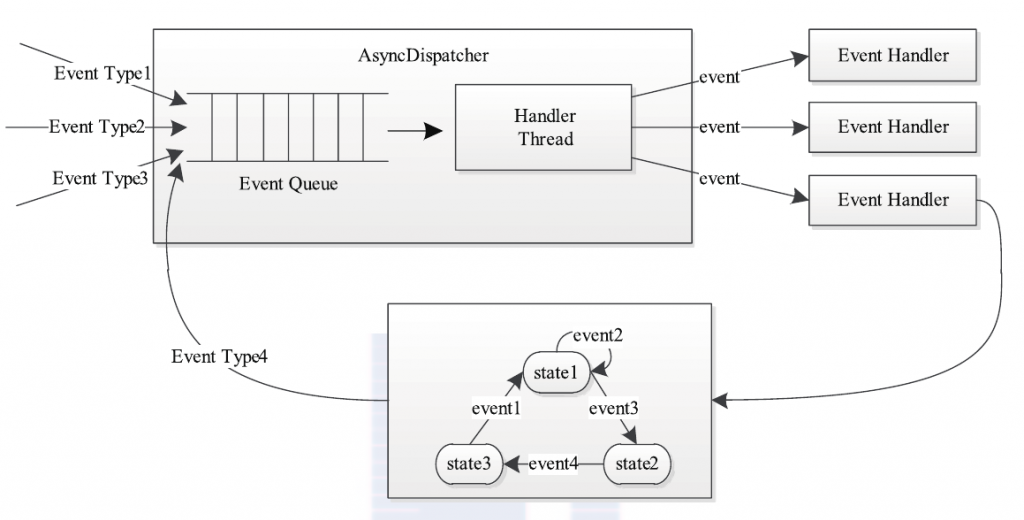
整个处理过程大致为:处理请求会作为事件进入系统,由中央异步调度器(Async-Dispatcher)负责传递给相应事件调度器(Event Handler)。该事件调度器可能将该事件转发给另外一个事件调度器,也可能交给一个带有有限状态机的事件处理器,其处理结果也以事 件的形式输出给中央异步调度器。而新的事件会再次被中央异步调度器转发给下一个事件调度器,直至处理完成(达到终止条件)。
在YARN 中,所有核心服务实际上都是一个中央异步调度器,包括ResourceManager、NodeManager、MRAppMaster(MapReduce 应 用 程 序 的 ApplicationMaster)等, 它们维护了事先注册的事件与事件处理器,并根据接收的事件类型驱动服务的运行。
YARN中事件与事件处理器类的关系(位于包org.apache.hadoop.yarn.event中)如下图所示。
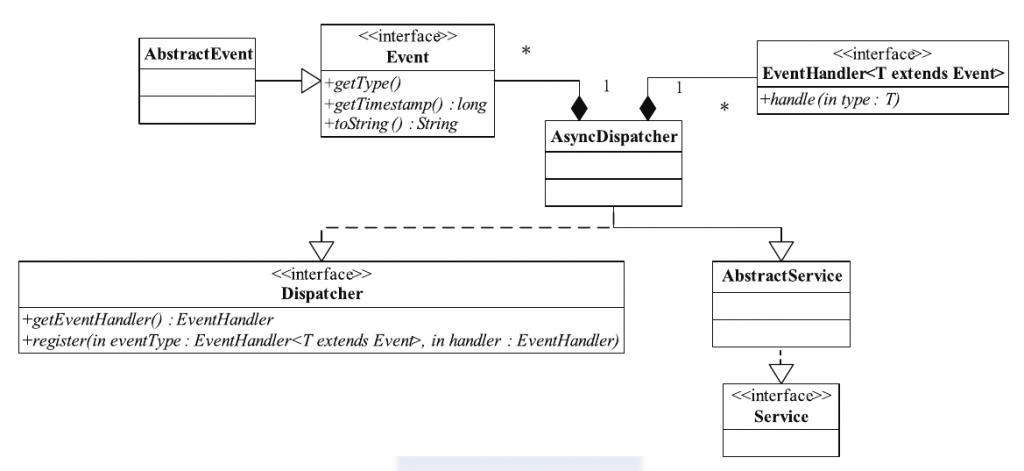
当使用YARN事件库时,通常先要定义一个中央异步调度器AsyncDispatcher,负责事件的处理与转发, 然后根据实际业务需求定义一系列事件 Event与事件处理器EventHandler,并注册到中央异步调度器中以实现事件统一管理和调度(异步调度器维护了Event与EventHandler之间的映射关系)。以MRAppMaster为例, 它内部包含一个中央异步调度器AsyncDispatcher,并注册了TaskAttemptEvent/TaskAttemptImpl、TaskEvent/TaskImpl、JobEvent/JobImpl 等一系列事件/事件处理器,由中央异步调度器统一管理和调度。
服务化和事件驱动软件设计思想的引入,使得YARN具有低耦合、高内聚的特点,各个模块只需完成各自功能,而模块之间则采用事件联系起来,系统设计简单且维护方便。
为了说明 YARN 服务库和事件库的使用方法,本小节介绍一个简单的实例,该实例可看做MapReduceApplicationMaster(MRAppMaster)的简化版。该例子涉及任务和作业两种对象的事件以及一个中央异步调度器。步骤如下。
步骤1 定义Task事件。
package org.qingyuanxingsi.test;
import org.apache.hadoop.yarn.event.AbstractEvent;
public class TaskEvent extends AbstractEvent<TaskEventType>{
//Task id
private String taskId;
public TaskEvent(String taskId,TaskEventType type){
super(type);
this.taskId = taskId;
}
public String getTaskId(){
return taskId;
}
}
其中,Task事件类型定义如下:
package org.qingyuanxingsi.test;
public enum TaskEventType{
T_KILL,
T_SCHEDULE
}
步骤2 定义Job事件。
package org.qingyuanxingsi.test;
import org.apache.hadoop.yarn.event.AbstractEvent;
public class JobEvent extends AbstractEvent<JobEventType>{
private String jobId;
public JobEvent(String jobId,JobEventType type) {
super(type);
// TODO Auto-generated constructor stub
this.jobId = jobId;
}
public String getJobId(){
return jobId;
}
}
其中,Job事件类型定义如下:
package org.qingyuanxingsi.test;
public enum JobEventType {
JOB_KILL,
JOB_INIT,
JOB_START
}
步骤3 事件调度器。 接下来定义一个中央异步调度器,它接收Job和Task两种类型事件,并交给对应的事件处理器处理,代码如下:
package org.qingyuanxingsi.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.service.CompositeService;
import org.apache.hadoop.service.Service;
import org.apache.hadoop.yarn.event.AsyncDispatcher;
import org.apache.hadoop.yarn.event.Dispatcher;
import org.apache.hadoop.yarn.event.EventHandler;
/**
* A simple central async dispatcher
* @author qingyuanxingsi
*
*/
public class SimpleMRAppMaster extends CompositeService {
//Central Async Dispatcher
private Dispatcher dispatcher;
@SuppressWarnings("unused")
private String jobId;
//The number of tasks contained in this job
private int taskNum;
//All tasks
private String[] taskIdArray;
public SimpleMRAppMaster(String name,String jobId,
int taskNum) {
super(name);
this.jobId = jobId;
this.taskNum = taskNum;
this.taskIdArray = new String[taskNum];
for(int i=0; i<taskNum; i++){
taskIdArray[i] = new String(jobId+"_task_"+i);
}
}
@Override
protected void serviceInit(Configuration conf) throws Exception {
// TODO Auto-generated method stub
dispatcher = new AsyncDispatcher();
//Register the event handler for job and task events
dispatcher.register(JobEventType.class, new JobEventDispatcher());
dispatcher.register(TaskEventType.class, new TaskEventDispatcher());
addService((Service)dispatcher);
super.serviceInit(conf);
}
public Dispatcher getDispatcher(){
return dispatcher;
}
private class JobEventDispatcher implements EventHandler<JobEvent>{
@SuppressWarnings("unchecked")
@Override
public void handle(JobEvent event) {
// TODO Auto-generated method stub
if(event.getType() == JobEventType.JOB_KILL){
System.out.println("Receive JOB_KILL event,killing all the tasks");
for(int i=0;i<taskNum;i++){
dispatcher.getEventHandler().handle(new TaskEvent(taskIdArray[i],
TaskEventType.T_KILL));
}
}
else if(event.getType() == JobEventType.JOB_INIT){
System.out.println("Receive JOB_Init event,initializing all the tasks");
for(int i=0;i<taskNum;i++){
dispatcher.getEventHandler().handle(new TaskEvent(taskIdArray[i],
TaskEventType.T_SCHEDULE));
}
}
}
}
@Override
protected void serviceStart() throws Exception {
// TODO Auto-generated method stub
super.serviceStart();
}
private class TaskEventDispatcher implements EventHandler<TaskEvent>{
@Override
public void handle(TaskEvent event) {
// TODO Auto-generated method stub
if(event.getType() == TaskEventType.T_KILL)
{
System.out.println("Killing this very task with taskId:"+event.getTaskId());
}
else if(event.getType() == TaskEventType.T_SCHEDULE)
{
System.out.println("Scheduling this very task with taskId:"+event.getTaskId());
}
}
}
}
步骤4 测试程序。
package org.qingyuanxingsi.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.yarn.conf.YarnConfiguration;
/**
* Just a simple test case
* @author qingyuanxingsi
* @version 1.0
*/
public class SimpleMRAppMasterTest {
@SuppressWarnings({ "unchecked", "resource" })
public static void main(String[] args){
String jobId = "job_20140321_01";
SimpleMRAppMaster master = new SimpleMRAppMaster("Simple MRAppMaster",jobId,5);
YarnConfiguration conf = new YarnConfiguration(new Configuration());
try {
master.serviceInit(conf);
master.serviceStart();
master.getDispatcher().getEventHandler().handle(new JobEvent(jobId,
JobEventType.JOB_KILL));
master.getDispatcher().getEventHandler().handle(new JobEvent(jobId,
JobEventType.JOB_INIT));
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
- https://developers.google.com/protocol-buffers/docs/javatutorial ↩
- http://avro.apache.org/docs/current/gettingstartedjava.html ↩
- 参考java动态代理(JDK和cglib) ↩
- 如若时间允许,该设计模式会进行详尽的分析。 ↩
- 其实其基本实现结构与Android Handler类似,有兴趣的朋友可以查阅一下相关资料。 ↩